Currently Lucene restricts dot_product to be only used over normalized vectors. Normalization forces all vector magnitudes to equal one. While for many cases this is acceptable, it can cause relevancy issues for certain data sets. A prime example are embeddings built by Cohere. Their vectors use magnitudes to provide more relevant information.
So, why not allow non-normalized vectors in dot-product and thus enable maximum-inner-product? What's the big deal?
Negative Values and Lucene Optimizations
Lucene requires non-negative scores, so that matching one more clause in a disjunctive query can only make the score greater, not lower. This is actually important for dynamic pruning optimizations such as block-max WAND, whose efficiency is largely defeated if some clauses may produce negative scores. How does this requirement affect non-normalized vectors?
In the normalized case, all vectors are on a unit sphere. This allows handling negative scores to be simple scaling.
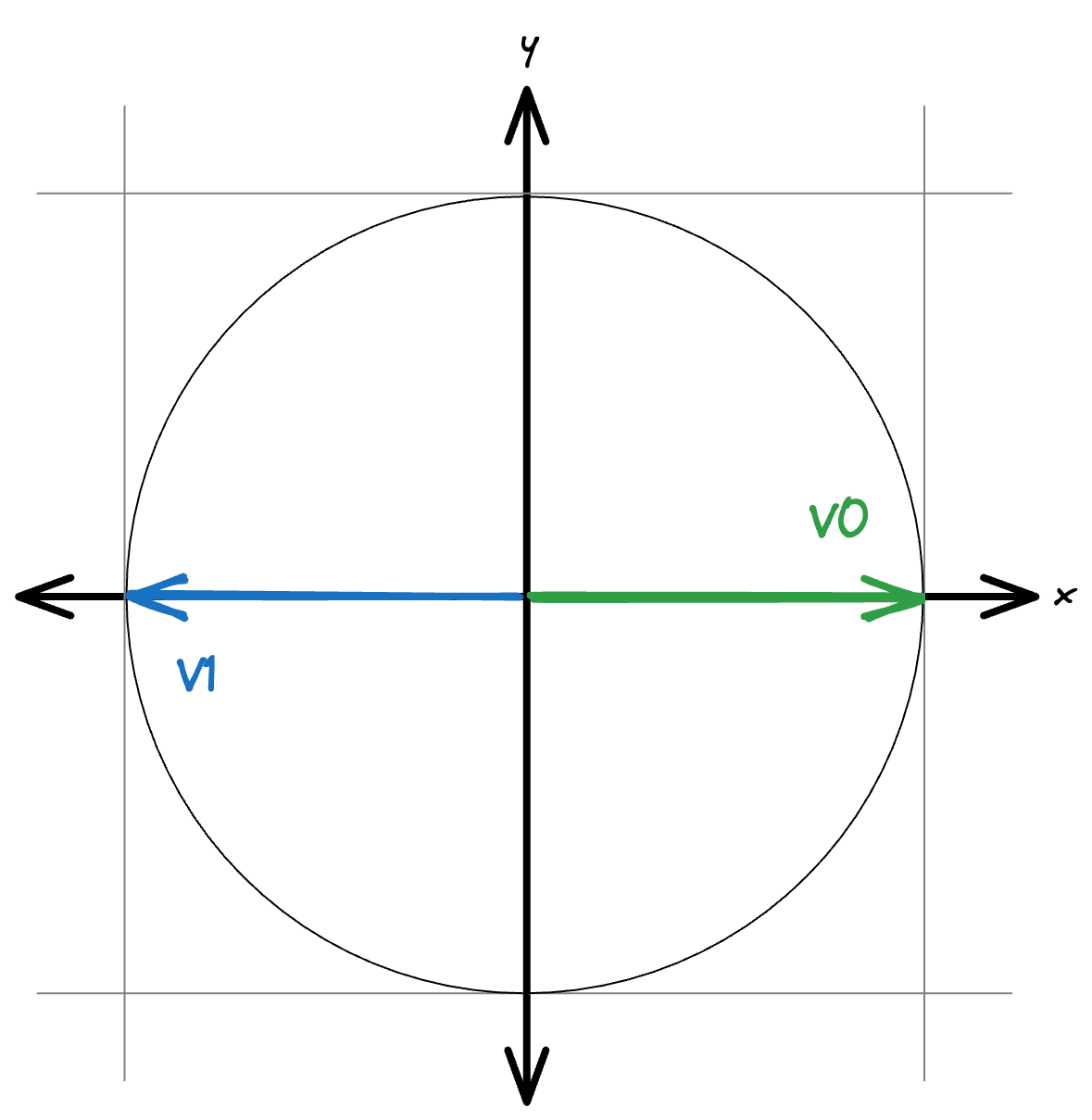
Figure 1: Two opposite, two dimensional vectors in a 2d unit sphere (e.g. a unit circle). When calculating the dot-product here, the worst it can be is -1 = [1, 0] * [-1, 0]. Lucene accounts for this by adding 1 to the result.
With vectors retaining their magnitude, the range of possible values is unknown.
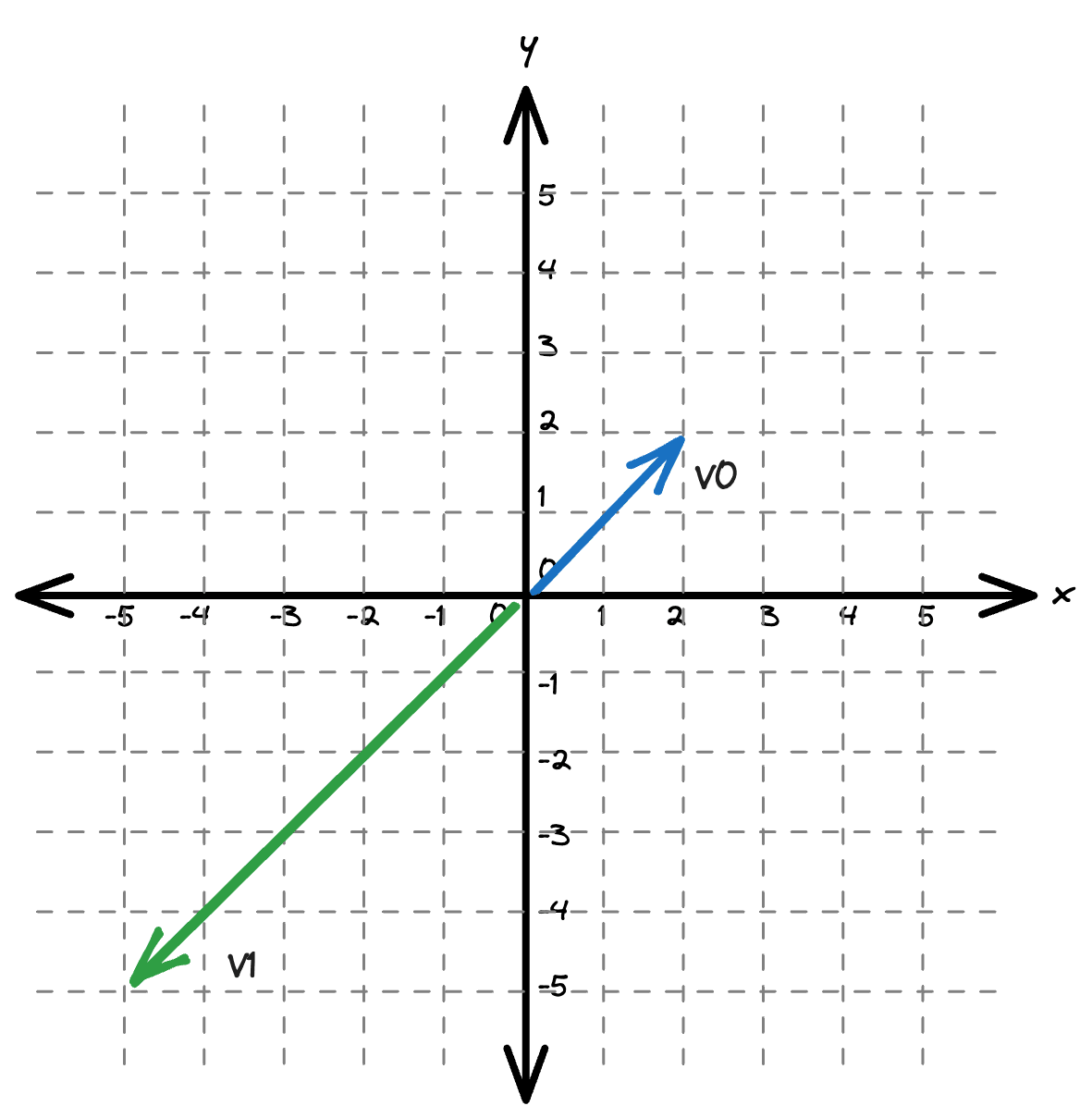
Figure 2: When calculating the dot-product for these vectors [2, 2] \* [-5, -5] = -20
To allow Lucene to utilize blockMax WAND with non-normalized vectors, we must scale the scores. This is a fairly simple solution. Lucene will scale non-normalize vectors with a simple piecewise function:
if (dotProduct < 0) {
return 1 / (1 + -1 * dotProduct);
}
return dotProduct + 1;Now all negative scores are between 0-1, and all positives are scaled above 1. This still ensures that higher values mean better matches and removes negative scores. Simple enough, but this is not the final hurdle.
The Triangle Problem
Maximum-inner-product doesn't follow the same rules as of simple euclidean spaces. The simple assumed knowledge of the triangle inequality is abandoned. Unintuitively, a vector is no longer nearest to itself. This can be troubling. Lucene’s underlying index structure for vectors is Hierarchical Navigable Small World (HNSW). This being a graph based algorithm, it might rely on euclidean space assumptions. Or would exploring the graph be too slow in non-euclidean space?
Some research has indicated that a transformation into euclidean space is required for fast search. Others have gone through the trouble of updating their vector storage enforcing transformations into euclidean space.
This caused us to pause and dig deep into some data. The key question is this: does HNSW provide good recall and latency with maximum-inner-product search? While the original HNSW paper and other published research indicate that it does, we needed to do our due diligence.
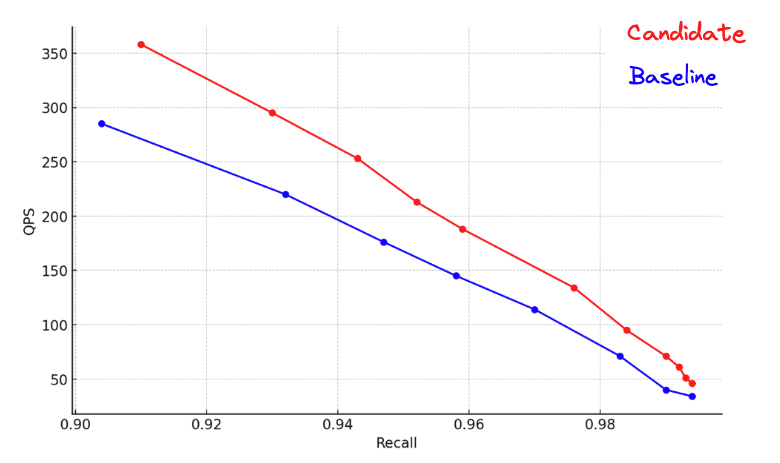
The experiments we ran were simple. All of the experiments are over real data sets or slightly modified real data sets. This is vital for benchmarking as modern neural networks create vectors that adhere to specific characteristics (see discussion in section 7.8 of this paper). We measured latency (in milliseconds) vs. recall over non-normalized vectors. Comparing the numbers with the same measurements but with a euclidean space transformation. In each case, the vectors were indexed into Lucene’s HNSW implementation and we measured for 1000 iterations of queries. Three individual cases were considered for each dataset: data inserted ordered by magnitude (lesser to greater), data inserted in a random order, and data inserted in reverse order (greater to lesser).
Here are some results from real datasets from Cohere:
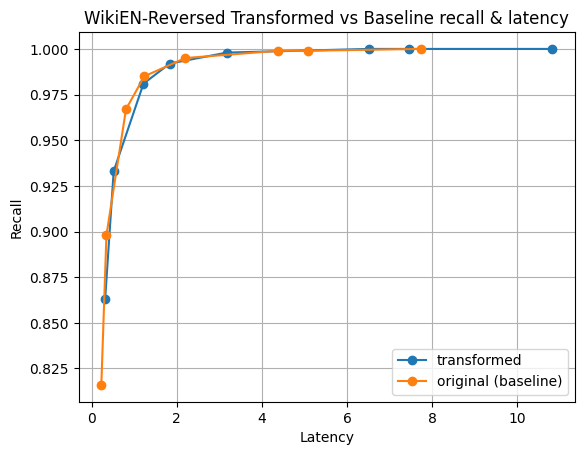
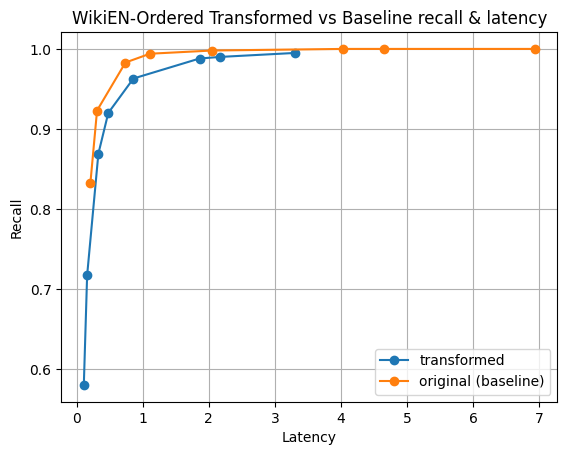
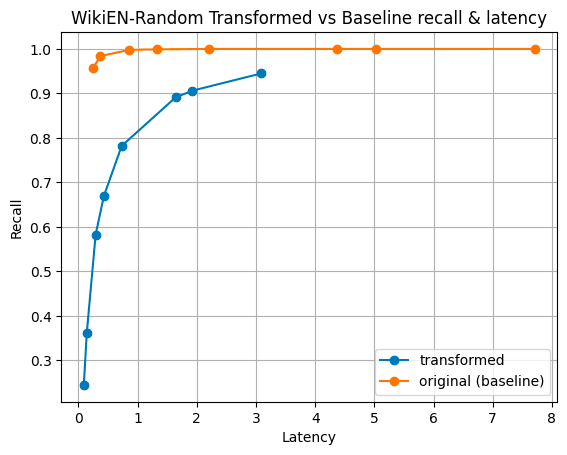
Figure 3: Here are results for the Cohere’s Multilingual model embedding wikipedia articles. Available on HuggingFace. The first 100k documents were indexed and tested.
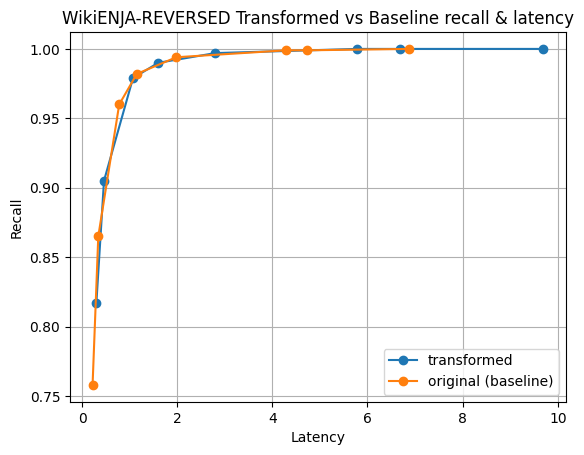
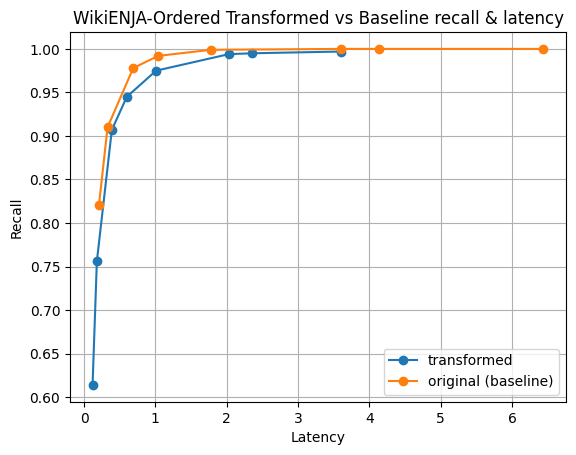
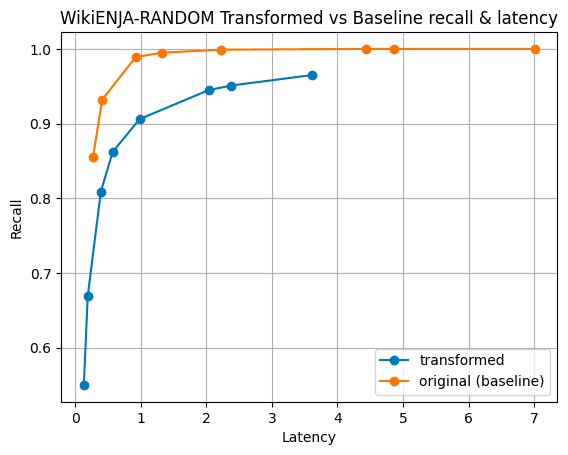
Figure 4: This is a mixture of Cohere’s English and Japanese embeddings over wikipedia. Both datasets are available on HuggingFace.
We also tested against some synthetic datasets to ensure our rigor. We created a data set with e5-small-v2 and scaled the vector's magnitudes by different statistical distributions. For brevity, I will only show two distributions.
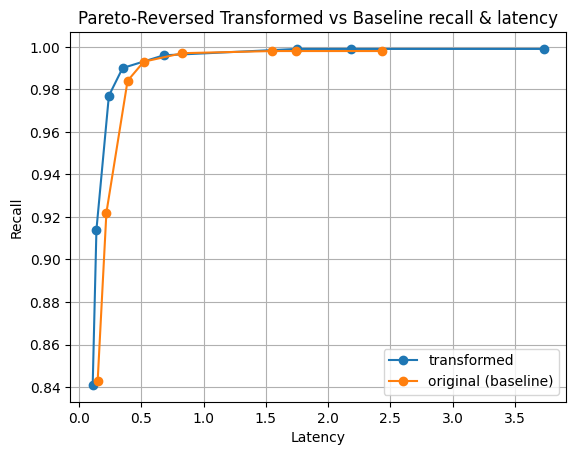
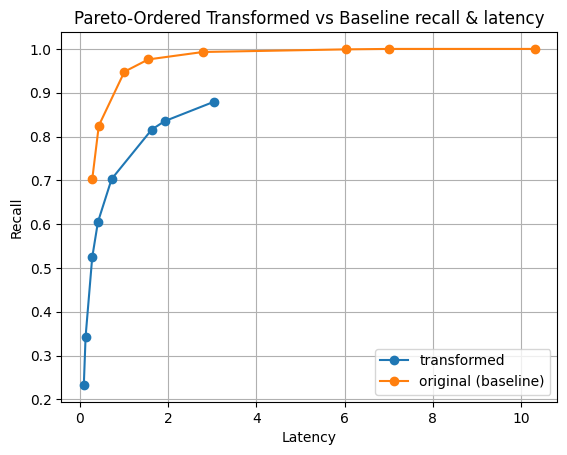
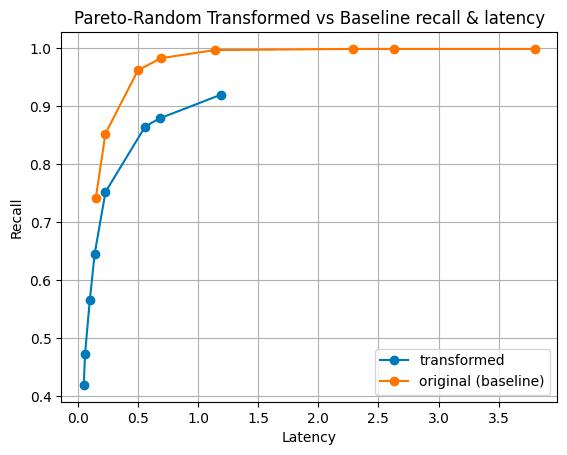
Figure 5: Pareto distribution of magnitudes. A pareto distribution has a “fat tail” meaning there is a portion of the distribution with a much larger magnitude than others.
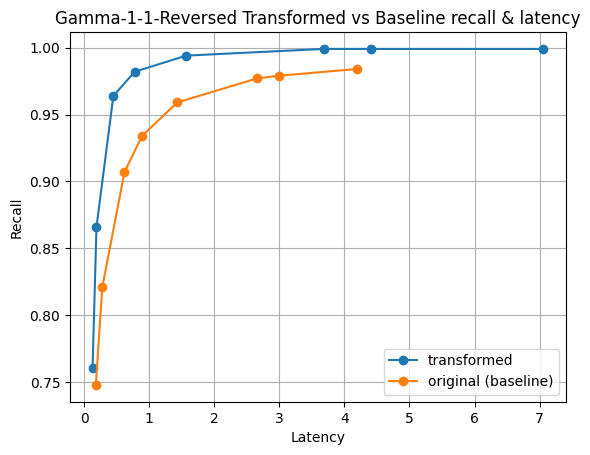
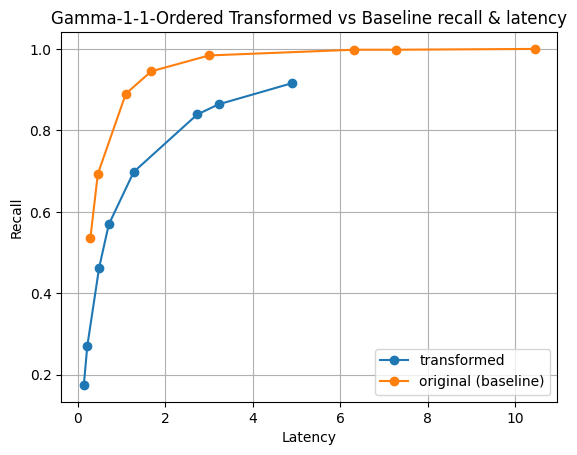
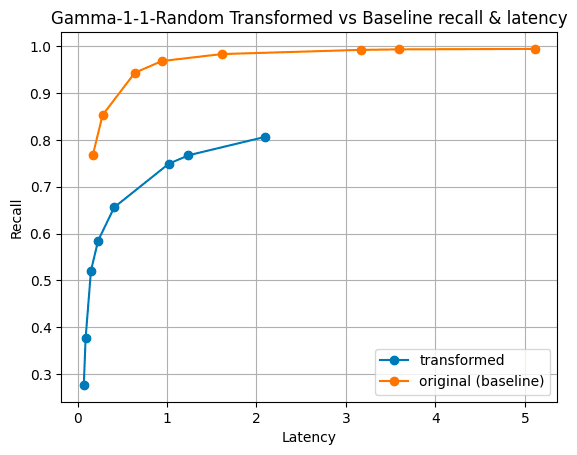
Figure 6: Gamma distribution of magnitudes. This distribution can have high variance and makes it unique in our experiments.
In all our experiments, the only time where the transformation seemed warranted was the synthetic dataset created with the gamma distribution. Even then, the vectors must be inserted in reverse order, largest magnitudes first, to justify the transformation. These are exceptional cases.
If you want to read about all the experiments, and about all the mistakes and improvements along the way, here is the Lucene Github issue with all the details (and mistakes along the way). Here’s one for open research and development!
Conclusion
This has been quite a journey requiring many investigations to make sure maximum-inner-product can be supported in Lucene. We believe the data speaks for itself. No significant transformations required or significant changes to Lucene. All this work will soon unlock maximum-inner-product support with Elasticsearch and allow models like the ones provided by Cohere to be first class citizens in the Elastic Stack.