Generative AI has recently created enormous successes and excitement, with models that can generate fluent text, realistic images, and even videos. In the case of language, large language models, trained on vast amounts of data, are capable on understanding context and generating relevant responses to questions. This blog post explores the challenges associated with Generative AI, how Retrieval Augmented Generation (RAG) can help overcome those challenges, how RAG works, as well as the advantages and challenges of using RAG.
Challenges with Generative AI
However, its important to understand that these models are not perfect. The knowledge that these models possess is parametric knowledge that they learned during training and is a condensed representation of the entire training dataset.
Lack of Domain Knowledge
These models should be able to generate good responses to questions about general knowledge seen in their training data. But they cannot reliably answer questions about facts which are not in their training dataset. If the model is well aligned it will refuse to answer such out-of-domain questions. However, it is possible it will simply make up answers (also known as hallucinating). For example, a general purpose model will typically understand in general terms that each company will have a leave policy, but it will not have any knowledge of my particular company's leave policy.
Frozen Parametric Knowledge
An LLM's knowledge is frozen, which means it doesn't know anything about events that happen post-training. This means it will not be able to reliably answer questions about current events. Models are typically trained to qualify the answers they give for such questions.
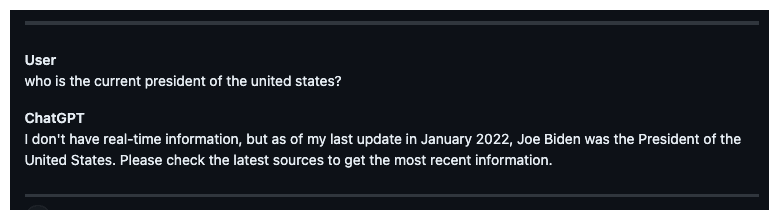
Hallucinations
It has been suggested that LLMs capture in their parameters something like a knowledge graph representation of general ontology: representing facts about and relationships between entities. Common facts that appear frequently in the training data are well represented in the knowledge graph. However, niche knowledge which is unlikely to have many examples in the training data is only approximately represented. As such LLMs have noisy understanding of such facts. The alignment process, where models are calibrated about what they know, is essential. Mistakes often occur in the gray area between known and unknown information, highlighting the challenge of distinguishing relevant details.
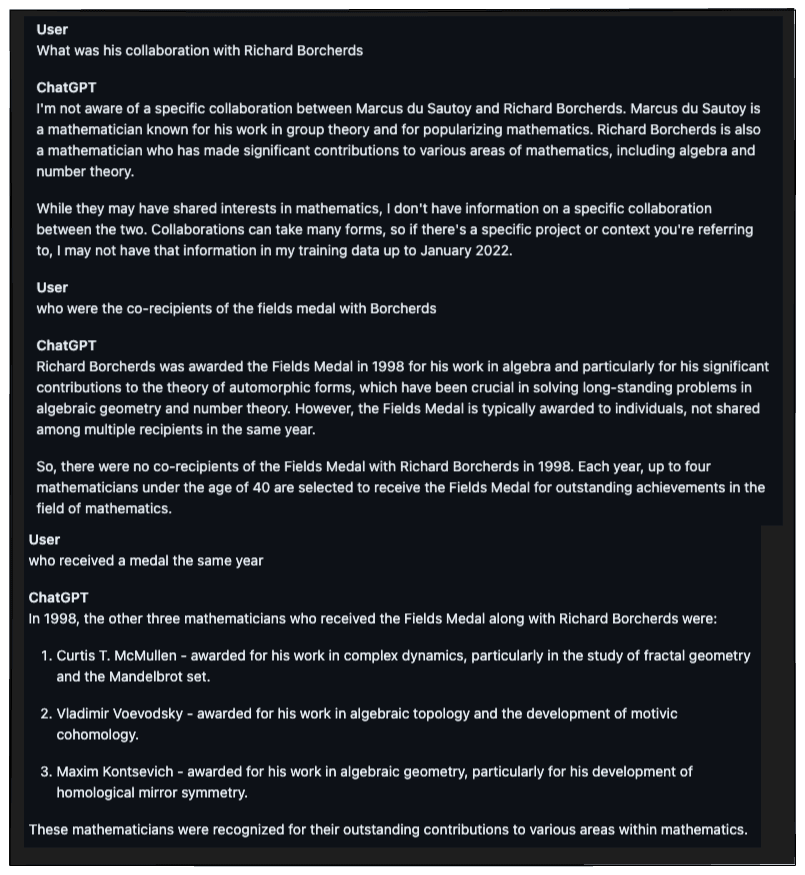
In the example above, the question about Fields Medal winners in the same year as Borcherds, is a prime example of this sort of niche knowledge. In this case we seeded the conversation with information about other mathematicians and ChatGPT appeared to get confused about what information to attend to. For example, it missed Tim Gowers and added Vladimir Voevodsky (who won in 2002).
Expensive to Train
While LLMs are capable of generating relevant responses to questions when trained on data within a specific domain, they are expensive to train and require vast amounts of data and compute to develop. Similarly, fine-tuning models requires expertise and time and there is the risk that in the process they "forget" other important capabilities.
How does RAG help solve this problem?
Retrieval Augmented Generation (RAG) helps solve this problem by grounding the parametric knowledge of a generative model with an external source knowledge, from a information retrieval system like a database. This source knowledge is passed as additional context to the model and helps the model generate more relevant responses to questions.
How does RAG work?
A RAG pipeline typically has three main components:
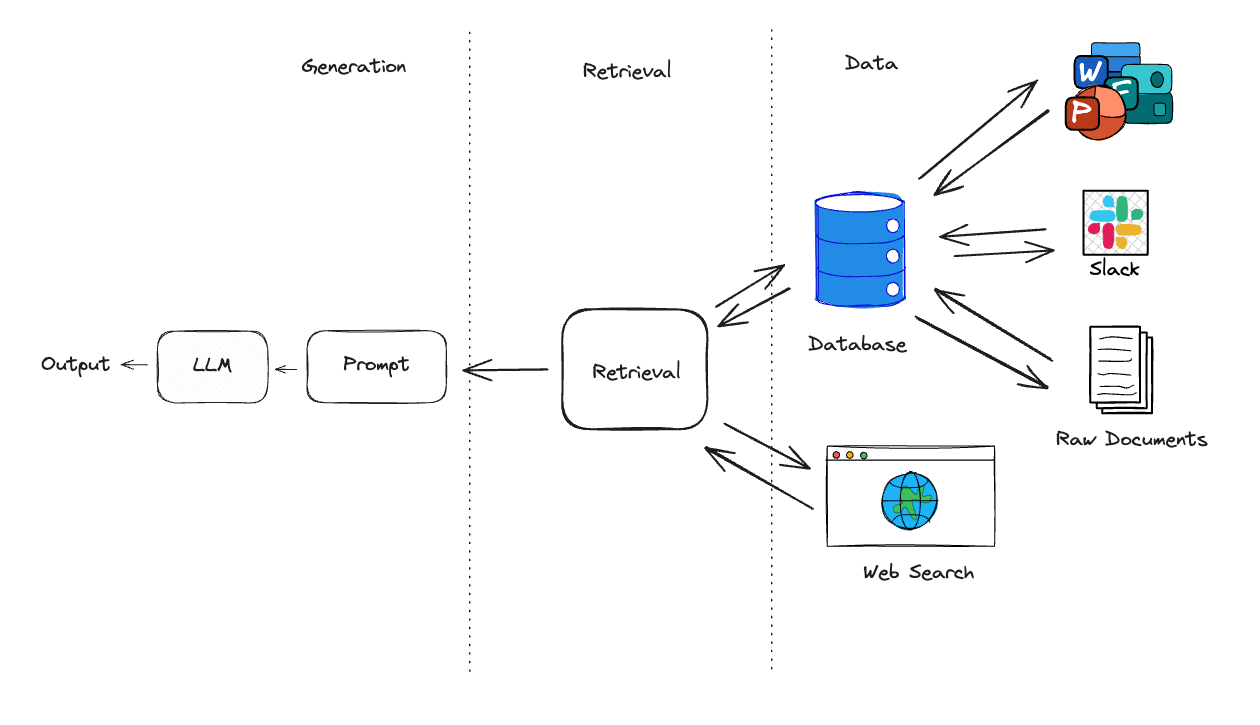
- Data: A collection of data (e.g documents, webpages) that contain relevant information to answer questions.
- Retrieval: A retrieval strategy that can retrieve relevant source knowledge from the data.
- Generation: With the relevant source knowledge, generate a response with the help of an LLM.
RAG Pipeline Flow
When directly interacting with a model, the LLM is given a question and generates a response based on its parametric knowledge. RAG adds an extra step to the pipeline, using retrieval to find relevant data that builds additional context for the LLM.
In the example below, we use a dense vector retrieval strategy to retrieve relevant source knowledge from the data. This source knowledge is then passed to the LLM as context to generate a response.
RAG doesn't have to use dense vector retrieval, it can use any retrieval strategy that can retrieve relevant source knowledge from the data. It could be a simple keyword search or even a Google web search.
We will cover other retrieval strategies in a future article.
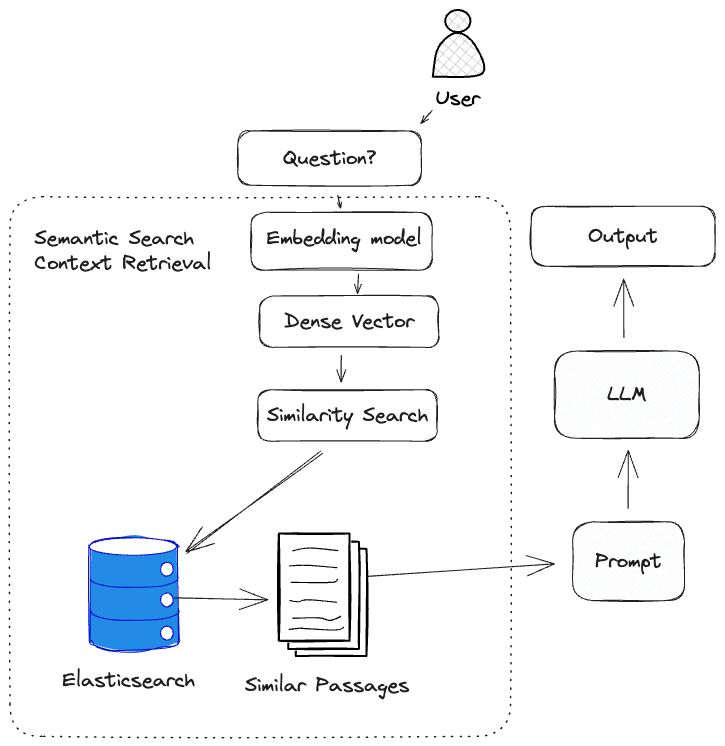
Retrieval of source knowledge
Retrieval of relevant source knowledge is key to answering the question effectively.
The most common approach for retrieval with Generative AI is using semantic search with dense vectors. Semantic search is a technique that requires an embedding model to transform natural language input into dense vectors which represent that source knowledge. We rely on these dense vectors to represent the source knowledge because they are able to capture the semantic meaning of the text. This is important because it allows us to compare the semantic meaning of the source knowledge with the question to determine if the source knowledge is relevant to the question.
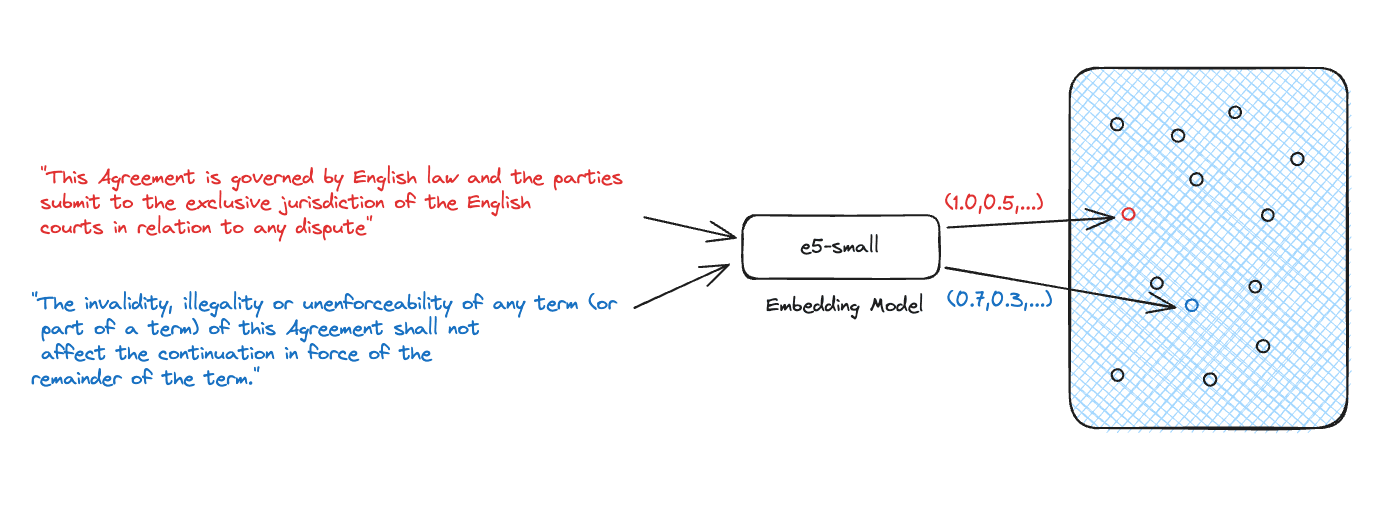
Given a question and its embedding, we can find the most relevant source knowledge.
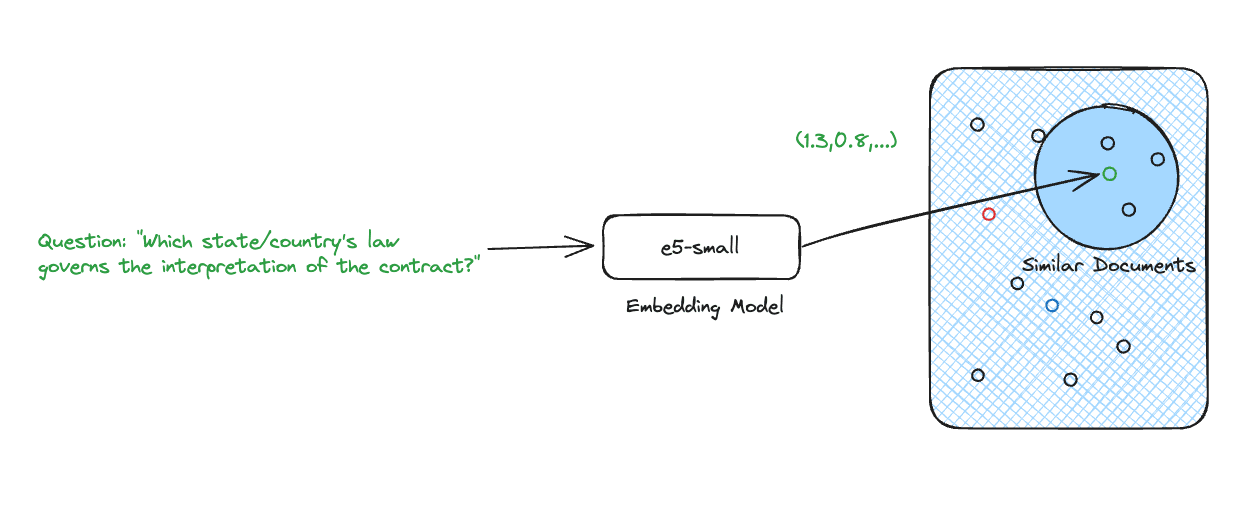
Semantic search with dense vectors isn't your only retrieval option, but it's one of the most popular approaches today. We will cover other approaches in a future article.
Advantages of RAG
After training, LLMs are frozen. The parametric knowledge of the model is fixed and cannot be updated. However, when we add data and retrieval to the RAG pipeline, we can update the source knowledge as the underlying data source changes, without having to retrain the model.
Grounded in Source Knowledge
The model's response can also be constrained to only use the source knowledge provided in-context, which helps limit hallucinations. This approach also opens up the option of using smaller, task-specific LLMs instead of large, general purpose models. This enables prioritizing the use of source knowledge to answer questions, rather than general knowledge acquired during training.
Citing Sources in Responses
In addition, RAG can provide clear traceability of the source knowledge used to answer a question. This is important for compliance and regulatory reasons and also helps spot LLM hallucinations. This is known as source tracking.
RAG in Action
Once we have retrieved the relevant source knowledge, we can use it to generate a response to the question. To do this, we need to:
Build a Context
A collection of source knowledge (e.g documents, webpages) that contain relevant information to answer questions. This provides the context for the model to generate a response.
Prompt Template
A template written in natural language for a specific task (answer questions, summarize text). Used as the input to the LLM.
Question
A question that is relevant to the task.
Once we have these three components, we can use the LLM to generate a response to the question. In the example below, we combine the prompt template with the user's question and the relevant passages retrieved. The prompt template builds the relevant source knowledge passages into a context.
This example also includes source tracing where the source knowledge passages are cited in the response.
Given the following extracted parts of a long document and a question, create an answer with references ("SOURCES").
If you don't know the answer, just say that you don't know. Don't try to make up an answer.
ALWAYS return a "SOURCES" part in your answer.
Question: "Which state/country's law governs the interpretation of the contract?"
=========
Content: This Agreement is governed by English law and the parties submit to the exclusive jurisdiction of the English courts in relation to any dispute (contractual or non-contractual) concerning this Agreement save that either party may apply to any court for an injunction or other relief to protect its Intellectual Property Rights.
Reference: 28-pl
Content: No Waiver. Failure or delay in exercising any right or remedy under this Agreement shall not constitute a waiver of such (or any other) right or remedy.\n\n11.7 Severability. The invalidity, illegality or unenforceability of any term (or part of a term) of this Agreement shall not affect the continuation in force of the remainder of the term (if any) and this Agreement.\n\n11.8 No Agency. Except as expressly stated otherwise, nothing in this Agreement shall create an agency, partnership or joint venture of any kind between the parties.\n\n11.9 No Third-Party Beneficiaries.
Reference: 30-pl
Content: (b) if Google believes, in good faith, that the Distributor has violated or caused Google to violate any Anti-Bribery Laws (as defined in Clause 8.5) or that such a violation is reasonably likely to occur,
Reference: 4-pl
=========Challenges with RAG
Effective retrieval is the key to answering questions effectively. Good retrieval provides a diverse set of relevant source knowledge to the context. However, this is more of an art than a science, requires a lot of experimentation to get right, and is highly dependent on the use case.
Precise Dense Vectors
Large documents are difficult to represent as a single dense vector because they contain multiple semantic meanings. For effective retrieval, we need to break down the document into smaller chunks of text that can be accurately represented as a single dense vector.
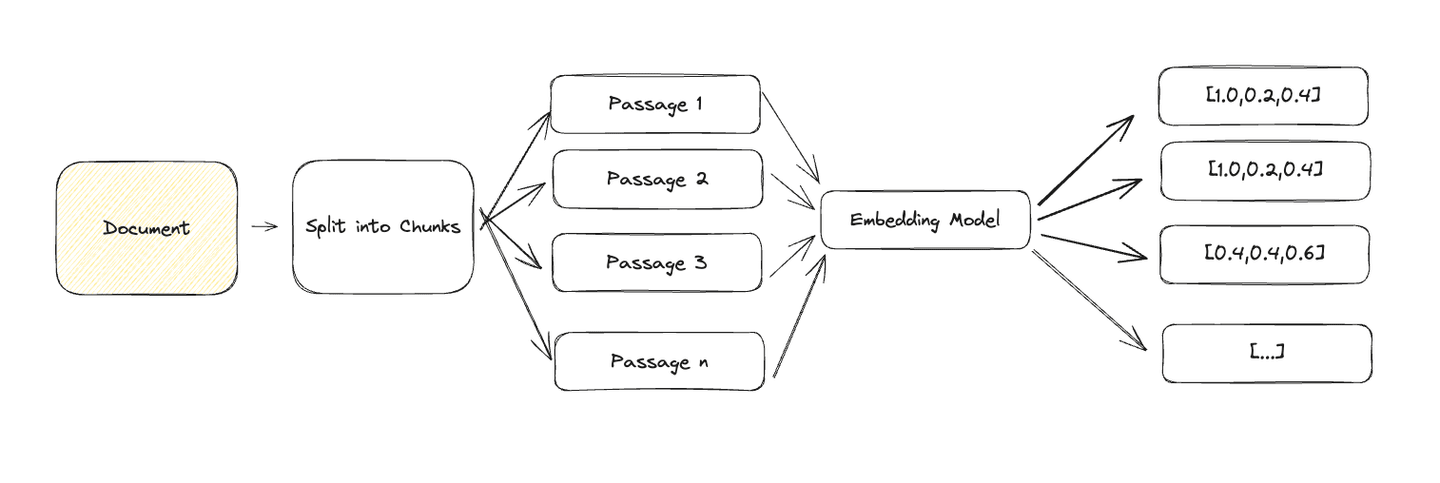
A common approach for generic text is to chunk by paragraphs and represent each paragraph as a dense vector. Depending on your use case, you may want to break the document down using titles, headings, or even sentences, as chunks.
Large Context
When using LLMs, we need to be mindful of the size of the context we pass to the model.
LLMs have a limit on the amount of tokens they can process at once. For example, GPT-3.5-turbo has a limit of 4096 tokens.
Secondly, responses generated may degrade in quality as the context increases, increasing the risk of hallucinations.
Larger contexts also require more time to process and, crucially, they increase LLM costs.
This comes back to the art of retrieval. We need to find the right balance between chunking size and accuracy with embeddings.
Conclusion
Retrieval Augmented Generation is a powerful technique that can help improve the quality of an LLM's generated responses, by providing relevant source knowledge as context. But RAG isn't a silver bullet. It requires a lot of experimentation and tuning to get right and it's also highly dependent on your use case.
In the next article, we will cover how to build a RAG pipeline using LangChain, a popular framework for working with LLMs.