Let's dive into how Kubernetes controller primitives are used at very large scale to power Elastic Cloud Serverless.
As part of engineering our Elastic Cloud Serverless offering, we have been through a major redesign of our Cloud Architecture. The new architecture allows us to leverage the Kubernetes ecosystem for a resilient and scalable offering across 3 Cloud Services Providers, in many regions across the globe.
Early on we decided to embrace Kubernetes, as the orchestration backend to run millions of containers for Serverless projects, but also as a composable platform that can be easily extended by our engineers to support various use cases. For example, provisioning new projects on demand, configuring Elasticsearch with object storage accounts, auto-scaling Elasticsearch and Kibana in the most performant and cost-effective way, provisioning fast local SSD volumes on-demand, metering resource usage, authenticating requests, scaling the fleet with more regions and clusters, and many more.
Many of the Kubernetes design principles have guided us in that process. We naturally ended up building a set of APIs and controllers that follow Kubernetes conventions, but we also adapted the controller paradigm at a higher level, as the way we orchestrate resources globally.
What does it look like in practice? Let's dive deep into some important aspects.
Global Control Plane, Regional Data Plane
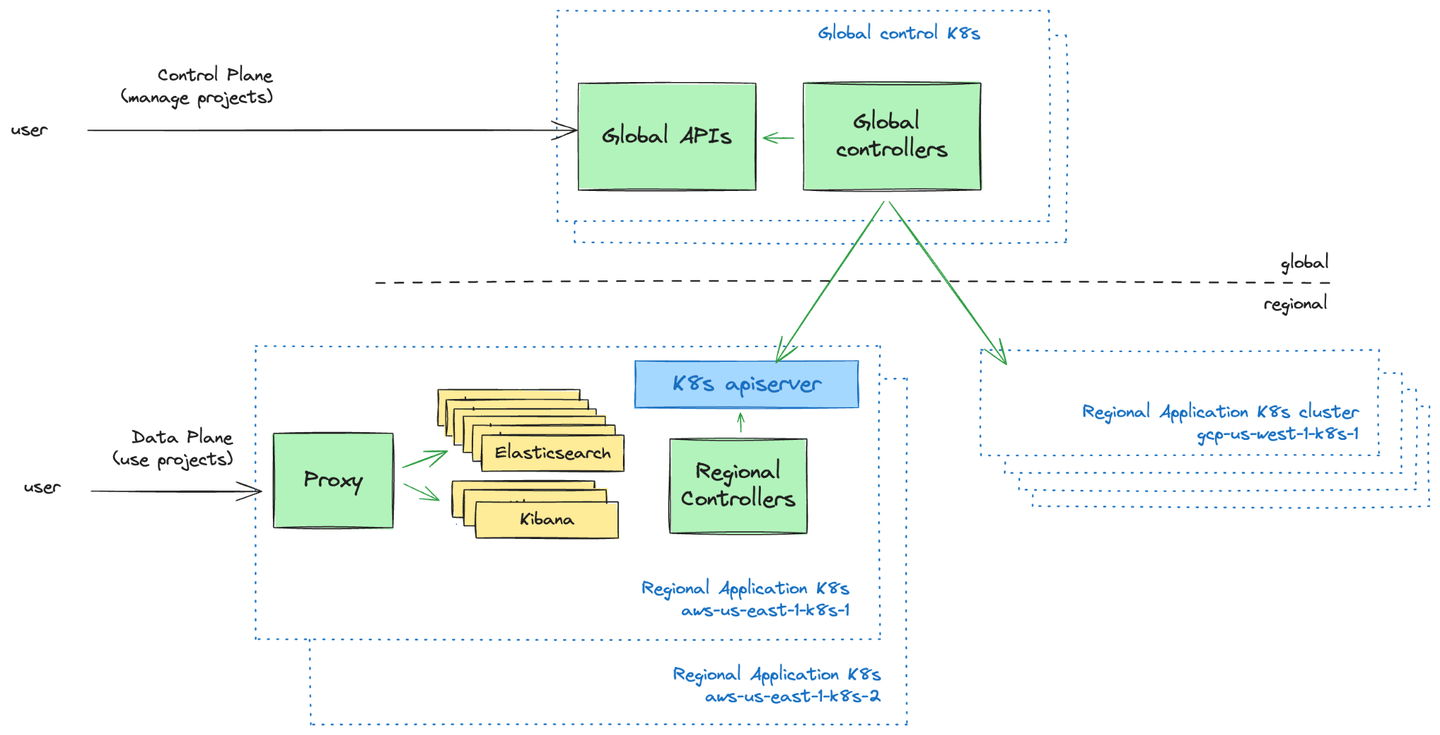
At a high-level, we can distinguish two high-level components:
-
The global control plane services, responsible for global orchestration of projects across regions and clusters. It also acts as a scheduler and decides which regional Kubernetes cluster will host which Elastic Cloud Serverless project.
-
The regional data plane services, responsible for orchestrating and running workloads at the scope of a single Kubernetes cluster. Each region can be made of several Kubernetes clusters, which we treat as disposable: they can be reconstructed from scratch at any time. This includes resources stored in the Kubernetes API Server, derived from the global control plane state.
Both components include a variety of services, though many of them are in practice implemented as APIs and controllers:
-
At the regional data plane level, they materialize as Custom Resource Definitions (CRDs) to declaratively specify entities manipulated by the system. They are stored as Custom Resources in the Kubernetes API Server, continuously reconciled by our custom controllers.
-
At the global control plane level, they materialize as HTTP REST APIs that persist their data in a globally-available, scalable and resilient datastore, alongside controllers that continuously reconcile those resources. Note that, while they look and feel like “normal” Kubernetes controllers, global controllers take their inputs from Global APIs and a global datastore, rather than from the Kubernetes API Server and etcd!
Controllers?
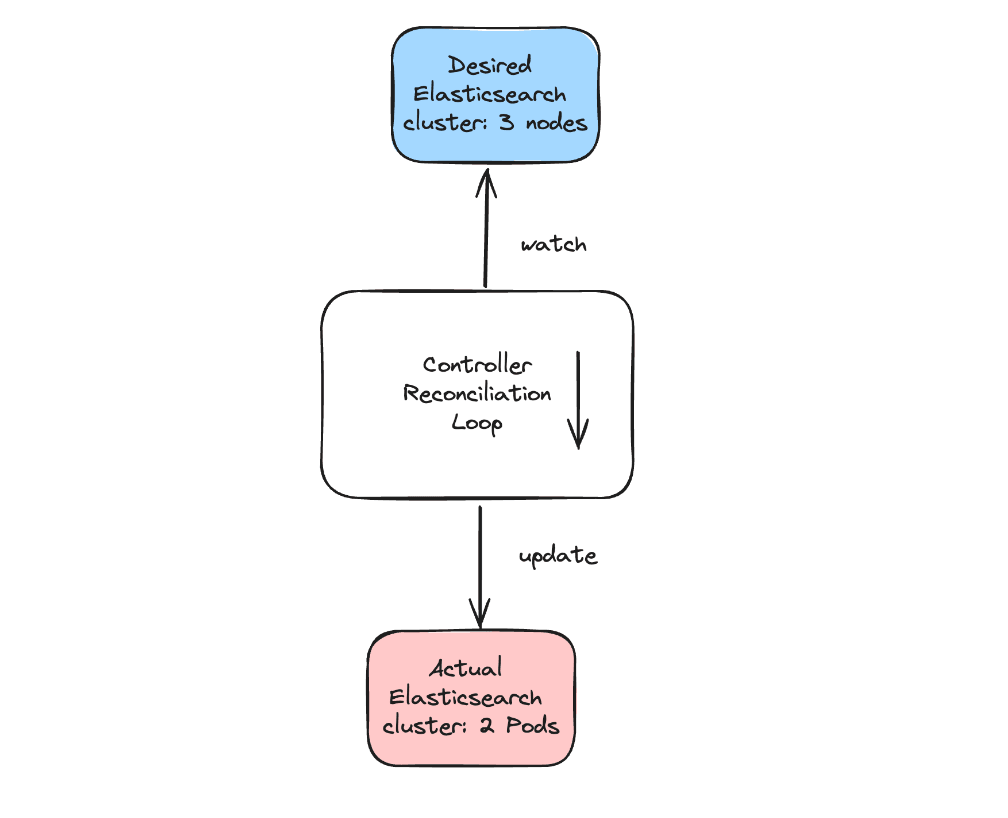
Kubernetes controllers behave in a simple, repeatable and predictable way. They are programmed to watch a source of events. On any event (creation, update, deletion), they always trigger the same reconciliation function. That function is responsible for comparing the desired state of a resource (for example, a 3-nodes Elasticsearch cluster) with the actual state of that resource (the Elasticsearch cluster currently has 2 nodes), and take action to reconcile the actual state towards the desired state (increase the number of replicas of that Elasticsearch deployment).
The controller pattern is convenient to work with for various reasons:
-
The level-triggered paradigm is simple to reason about. Asynchronous flows in the system are always encoded in terms of moving towards a declarative desired state, no matter what was the event that led to that desired state. This contrasts with an edge-triggered flow that considers every single variation of state (a configuration change, a version upgrade, a scale-up, a resource creation, etc.), and sometimes leads to modeling complex state machines.
-
It is resilient to failures and naturally leads to a design where resources get self-repaired and self-healed automatically. Missing an intermediate event does not matter, as long as we can guarantee the latest desired state will get processed.
-
Part of the Kubernetes ecosystem, the controller-runtime library comes with batteries included to easily build new controllers, as it abstracts away a number of important technical considerations: interacting with custom resources, watching through the API Server efficiently, caching objects for cheap reads, and enqueueing reconciliations automatically through a workqueue.
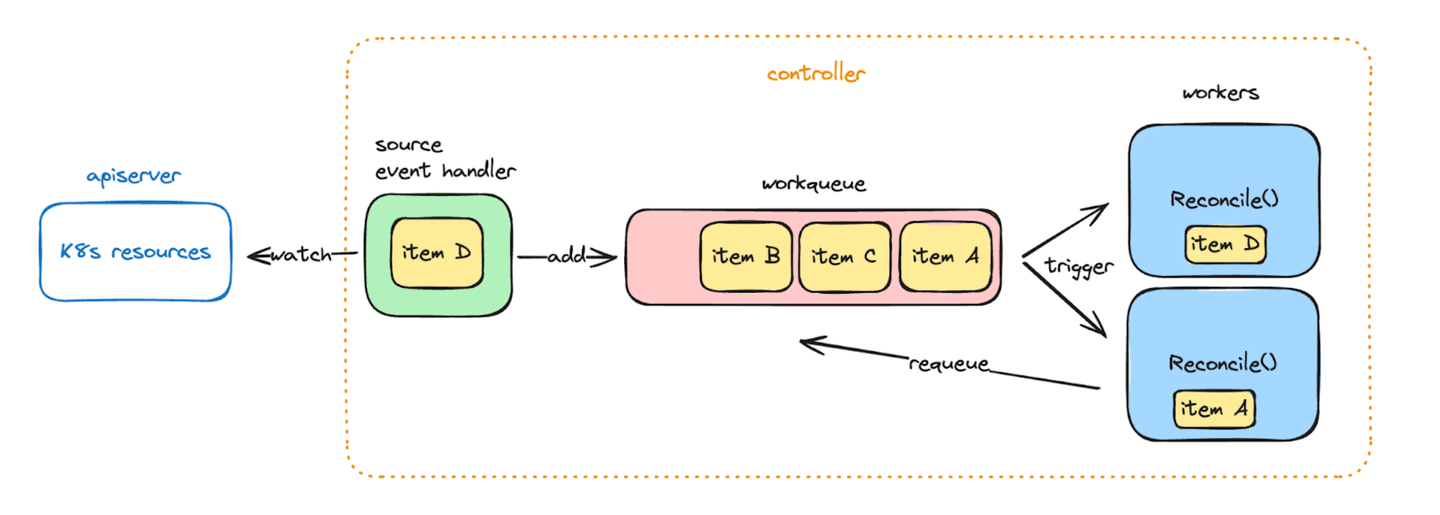
The workqueue itself holds some interesting properties:
-
Items are de-duplicated. If an item needs to be reconciled twice, due to two consecutive watch events, we just need to ensure the latest version of the object has been processed at least once.
-
Failed reconciliations can easily be retried by appending the item again to the same workqueue. Those retries are automatically rate-limited, with an exponential backoff.
-
The workqueue is populated automatically with all existing resources at controller startup. This ensures all items have been reconciled at least once, and covers for any missed event while the controller was unavailable.
Global controller and global datastore
The controller pattern and its internal workqueue fit very nicely with the needs of our regional data plane controllers. Conceptually, it would also apply quite well to our global control plane controllers! However, things get a bit more complicated there:
- As an important design principle for our backend, Kubernetes clusters and their state stored in etcd should be disposable. We want the operational ability to easily recreate and repopulate a Kubernetes cluster from scratch, with no important data or metadata loss. This led us to a strong requirement for our global state datastore: in case of regional failure, we want a multi-region failover with Recovery Point Objective (RPO) of 0, to ensure no data loss for our customers. The apiserver and etcd do not guarantee this by default.
- Additionally, while the regional data plane Kubernetes clusters have a strict scalability upper bound (they can’t grow larger than we want them to!), data in the global control plane datastore is conceptually unbounded. We want to support running millions of Serverless projects on the platform, and therefore require the datastore to scale along with the persisted data and query load, for a total amount of data that can be much larger than the amount of RAM on a machine.
- Finally, it is convenient for Global API services to work with the exact same data that global controllers are watching, and be able to serve arbitrarily complex SQL-like queries to fetch that data. The Kubernetes apiserver and etcd, as a key-value store, are not primarily designed for this use case.
With these requirements in mind, we decided to not persist the global control plane data in the Kubernetes API, but rather in an external strongly consistent, highly-available and scalable general-purpose database.
Fortunately, controller-runtime allows us to easily customize the source stream of events that trigger reconciliations. In just a few lines of code we were able to pipe our own logic of watching events from the global datastore into the controller. With this, our global controllers code largely look like regular Kubernetes controllers, while interacting with a completely different datastore.
func setupController(mgr ctrl.Manager, opts controller.Options) error {
// create a new controller-runtime controller
ctrl, err := controller.New("project-controller", mgr, opts)
if err != nil {
return err
}
// pipe datastore events through a K8s-like event channel
events := make(chan event.GenericEvent)
datastore.Watch(func(change T) {
objectID := change.ID()
// transform project change into a generic K8s-like event
events <- event.GenericEvent{Object: &Event[T]{
ObjectMeta: metav1.ObjectMeta{Name: objectID}}},
})
// trigger controller reconciliations from the events channel
return ctrl.Watch(
&source.Channel{Source: events},
GenericEventHandler(events)
)
}
func (c *Controller[T]) Reconcile(ctx context.Context, req ctrl.Request) (ctrl.Result, error) {
id := ProjectID(req.Name)
err := c.GetProject(id)
// reconcile!
}Workqueue optimizations at large scale
What happens once we have 200,000 items in the global datastore that need to be reconciled at startup of a global controller? We can control the concurrency of reconciliations (MaxConcurrentReconciles=N), to consume the workqueue in parallel, with uniqueness guarantees that avoid concurrent processing of the same item.
The degree of parallelism needs to be carefully thought through. If set too low, processing all items will take a very long time. For example, 200,000 items with an average of 1 second reconciliation duration and MaxConcurrentReconciles=1 means all items will only be processed after 2.3 days. Worse, if a new item gets created during that time, it may only be processed for the first time 2.3 days after creation! On the other hand, if MaxConcurrentReconciles is set too high, processing a very large number of items concurrently will dramatically increase CPU and IO usage, which generally also means increasing infrastructure costs. Can the global datastore handle 200,000 concurrent requests? How much would it then cost?
To better address the trade-off, we decided to categorize reconciliations into 3 buckets:
-
Items that need to be reconciled as soon as possible. Because they have been recently created/updated/deleted, and never successfully reconciled since then. These fit in a “high-priority reconciliations” bucket.
-
Items that have already been reconciled successfully at least once with their current specification. The main reason why those need to be reconciled again is to ensure any code change in the controller will eventually be reflected through a reconciliation on existing resources. These can be processed reasonably slowly over time, since there should be no customer impact from delaying their reconciliation. These fit in a “low-priority reconciliations” bucket.
-
Items that we know need to be reconciled at a particular point in time in the future. For example, to respect a soft-deletion period of 30 days, or to ensure their credentials are rotated every 24h. Those fit in a “scheduled reconciliations” bucket.
This can be implemented through a similar mechanism as Generation and ObservedGeneration in some Kubernetes resources. On any change in the specification of a project, we persist the revision of that specification (a monotonically increasing integer). At the end of a successful reconciliation, we persist the revision that was successfully reconciled. To know whether an item deserves to be reconciled immediately, hence be put in the high-priority bucket, we can compare both revisions values. In case the reconciliation failed, it is enqueued again for being retried.
type Project struct {
ID string
Revision int64
// ...
Status struct {
LastReconciledRevision int64
}
}
func (p Project) IsPendingChanges() bool {
return p.Revision != p. LastReconciledRevision
}
func (e *PrioritizedEventHandler) Generic(_ context.Context, evt event.GenericEvent) {
project := fromEvent(evt) // generic watch event includes the entire object
if project. IsPendingChanges() {
// high priority
e.workqueue.Add(reconcileReq)
} else {
// low priority
e.workqueue.AddLowPriority(reconcileReq)
}
}We can then plug the controller reconciliation event handling logic to append the item in the appropriate workqueue. A separate low-priority workqueue is consumed asynchronously at a fixed rate (for example, 300 items per minute). Those consumed items then get appended to the main high-priority workqueue for immediate processing by the available controller workers.
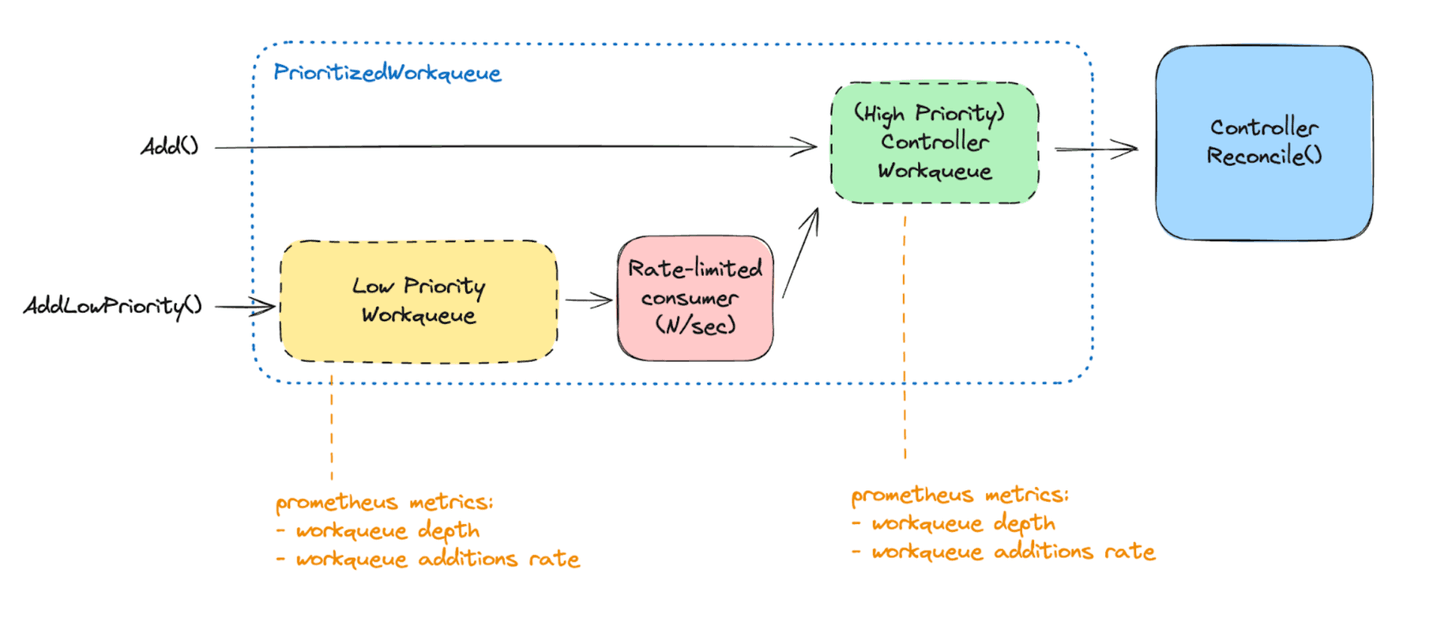
The controller then in practice works with two different workqueues. Since both rely on regular controller-runtime workqueues implementations, we benefit from built-in Prometheus metrics. Those allow monitoring the depth of the low-priority workqueue, for example, as a good signal of how many controller startup reconciliations are still pending. And the additions rate to the high priority workqueue, which indicates how much “urgent” work we're asking from the controller.
Conclusion
Kubernetes is a fascinating project. We have taken a lot of inspiration from its design principles and extension mechanisms. For some of them, extending their scope beyond the ability to manage resources in a single Kubernetes cluster, towards the ability to work with a highly-scalable datastore, with controllers able to reconcile resources in thousands of Kubernetes clusters across Cloud Service Providers regions. It has proven to be a fundamental part of our internal platform at Elastic, and allows us to develop and deliver new services and features to Elastic users every day.
Stay tuned for more technical details in future posts. You can also check out talks by Elastic engineers at the last Kubecon + CloudNativeCon 2024:




