Introduction
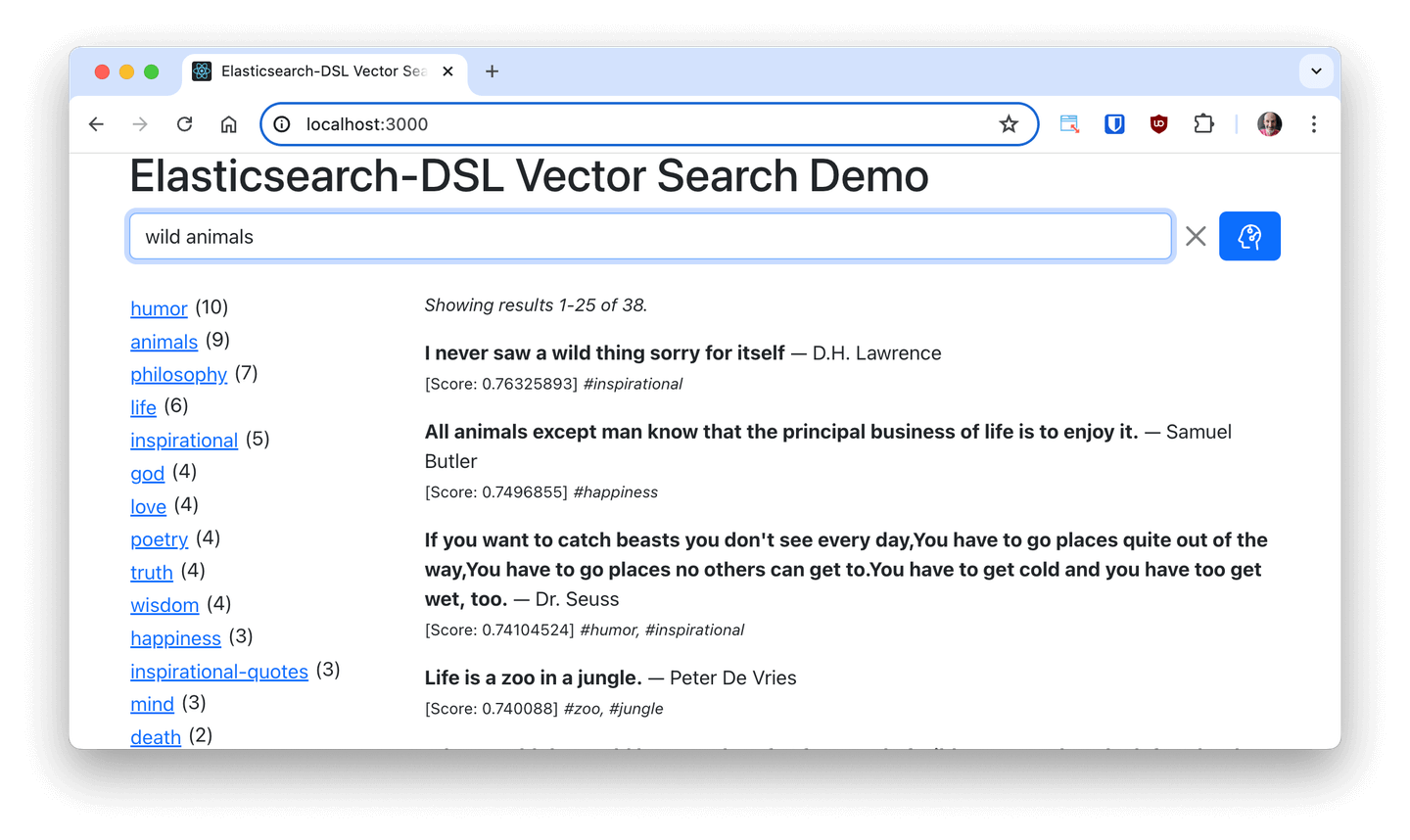
Do you want to build a RAG application on top of Elasticsearch vector database? Do you need to use semantic search on a large amount of data? Do you need to run on-premises in an air-gapped environment? This article will show you how.
Elasticsearch offers a number of ways to create embeddings for your data for symmetric search. One of the most popular ways is to use the Elasticsearch open inference API with OpenAI, Cohere, or Hugging Face models. These platforms support a number of large, powerful models for embedding that can run on GPUs. However, third-party embedding services are not available for the air-gapped systems or are off-limits to customers with privacy concerns and regulatory requirements.
Alternatively, you can use ELSER and E5 to compute embeddings locally. These embedding models run on the CPU and are optimized for speed and memory usage. They are also available for air-gapped systems and can be used in the cloud. However, the performance of these models is not as good as the models that run on GPUs.
Wouldn't it be great if you could compute embeddings for your data locally? With LocalAI you can do just that. LocalAI is a free and open-source inference server compatible with the OpenAI API. It supports model inference using multiple backends, including Sentence Transformers for embedding and llama.cpp for text generation. LocalAI also supports GPU acceleration, so you can compute embeddings faster.
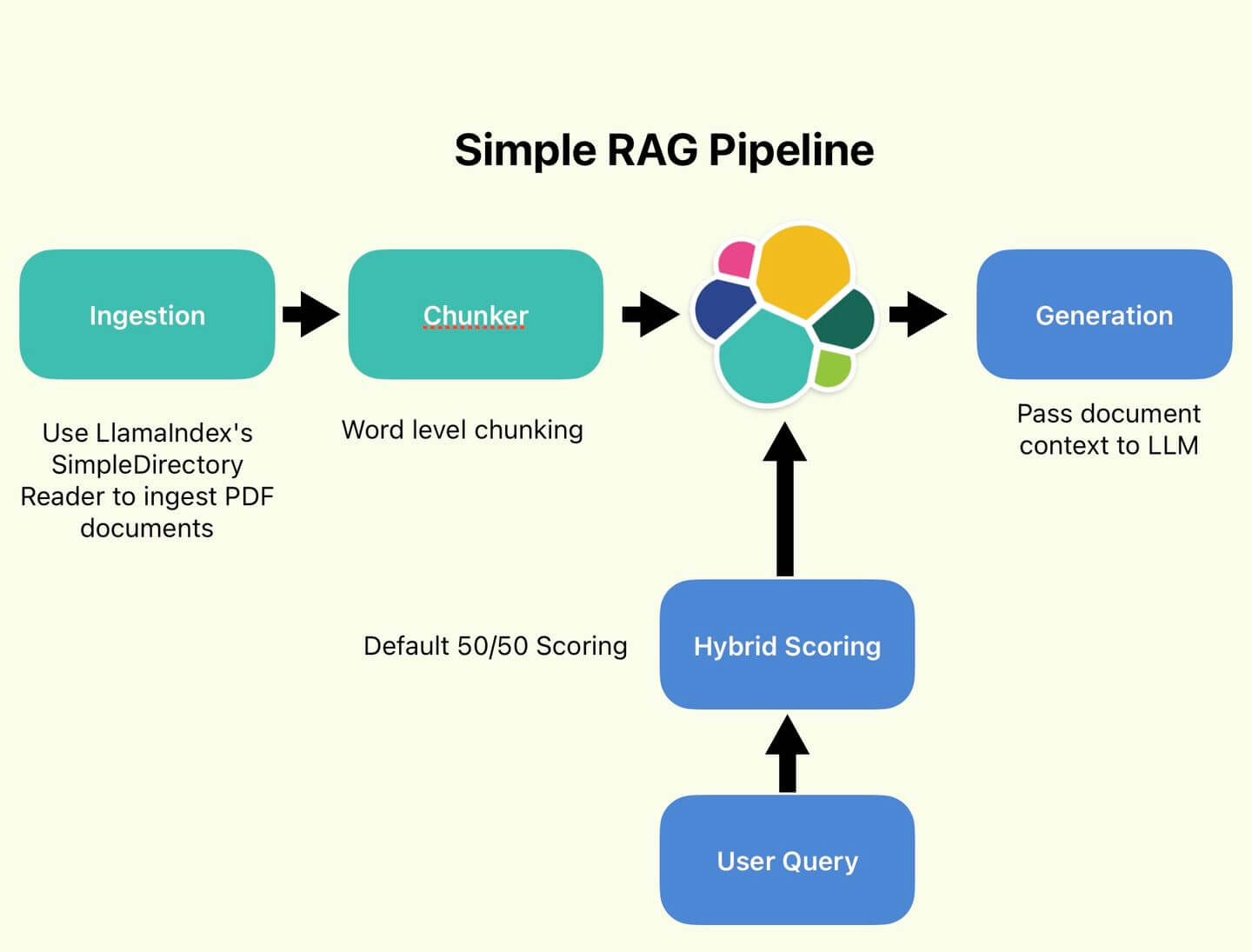
This article will show you how to use LocalAI to compute embeddings for your data. We'll walk you through the process of setting up LocalAI, configuring it to compute embeddings for your data, and running it to generate embeddings. You can run it on your laptop, on your air-gapped system, or wherever you need to compute embeddings.
Have I piqued your interest? Let's get started!
How to set up LocalAI to compute embeddings for your data
Step 1: Set up LocalAI with docker-compose
To get started with LocalAI, you need to have Docker and docker-compose installed on your machine. Depending on your operating system, you may also need to install NVIDIA Container Toolkit for GPU support inside the Docker containers.
Older versions do not support NVIDIA runtime directives, so make sure you have the latest version of docker-compose installed:
sudo curl -L https://github.com/docker/compose/releases/download/v2.26.0/docker-compose-`uname -s`-`uname -m` -o /usr/local/bin/docker-compose
sudo chmod +x /usr/local/bin/docker-composeCheck the version of docker-compose:
docker-compose --versionYou need to use the following docker-compose.yaml configuration file
# file: docker-compose.yaml
services:
localai:
image: localai/localai:latest-aio-gpu-nvidia-cuda-12
container_name: localai
environment:
- MODELS_PATH=/models
- THREADS=8
ports:
- "8080:8080"
volumes:
- $HOME/models:/models
tty: true
stdin_open: true
restart: always
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: all
capabilities: [gpu]Notes:
- We mount the
$HOME/modelsdirectory to the/modelsdirectory inside the container. This is where the models will be stored. You need to adjust the path to the directory where you want to store the models. - We have specified the number of threads to use for inference and the number of GPUs to use. You can adjust these values according to your hardware configuration.
Step 2: Configure LocalAI to use Sentence Transformers models
In this tutorial, we'll use the mixedbread-ai/mxbai-embed-large-v1, which is currently ranked 4th on the MTEB Leaderboard. However, any embedding model that can be loaded by the sentence-transformers library would work in the same way.
Create directory $HOME/models and a configuration file $HOME/models/mxbai-embed-large-v1.yaml with the following content:
# file: mxbai-embed-large-v1.yaml
name: mxbai-embed-large-v1
backend: sentencetransformers
embeddings: true
parameters:
model: mixedbread-ai/mxbai-embed-large-v1Step 3: Start the LocalAI server
Start the Docker container in the detached mode by running
docker-compose up -dfrom your $HOME directory.
Verify that the container has started correctly by running docker-compose ps. Checking that the localai container is in the Up state.
You should see the output similar to the following:
~$ docker-compose ps
WARN[0000] /home/valeriy/docker-compose.yaml: `version` is obsolete
NAME IMAGE COMMAND SERVICE CREATED STATUS PORTS
localai localai/localai:latest-aio-gpu-nvidia-cuda-12 "/aio/entrypoint.sh" localai About a minute ago Up About a minute (health: starting) 0.0.0.0:8080->8080/tcpIf something went wrong, check the logs. You can also use the logs to verify that localai can see the GPU. Running
docker logs localaishould be able to see the information like this:
$ docker logs localai
===> LocalAI All-in-One (AIO) container starting...
NVIDIA GPU detected
Thu Mar 28 11:15:41 2024
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 535.86.10 Driver Version: 535.86.10 CUDA Version: 12.2 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 Tesla T4 Off | 00000000:00:04.0 Off | 0 |
| N/A 59C P0 29W / 70W | 2MiB / 15360MiB | 6% Default |
| | | N/A |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
| No running processes found |
+---------------------------------------------------------------------------------------+
NVIDIA GPU detected. Attempting to find memory size...
Total GPU Memory: 15360 MiBFinally, you can verify that the inference server is working by querying the list of installed models:
curl -k http://localhost:8080/v1/modelsshould produce output like this:
{"object":"list","data":[{"id":"tts-1","object":"model"},{"id":"text-embedding-ada-002","object":"model"},{"id":"gpt-4","object":"model"},{"id":"whisper-1","object":"model"},{"id":"stablediffusion","object":"model"},{"id":"gpt-4-vision-preview","object":"model"},{"id":"MODEL_CARD","object":"model"},{"id":"llava-v1.6-7b-mmproj-f16.gguf","object":"model"},{"id":"voice-en-us-amy-low.tar.gz","object":"model"}]}Step 4: Create Elasticsearch _inference service
We have created and configured the LocalAI inference server. Since it is a drop-in replacement for the OpenAI inference server, we can create a new openai inference service in Elasticsearch. Support for this functionality `was implemented in Elasticsearch 8.14.
To create a new inference service, open Dev Tools in Kibana and run the following command:
PUT _inference/text_embedding/mxbai-embed-large-v1
{
"service": "openai",
"service_settings": {
"model_id": "mxbai-embed-large-v1",
"url": "http://localhost:8080/embeddings",
"api_key": "ignored"
}
}Notes:
- The
api_keyparameter is required for theopenaiservice and must be set, but the specific value is not important for our LocalAI service. - For large models, the
PUTrequest may initially time out if the model takes a long time to download to the LocalAI server for the first time. Just retry thePUTrequest after a short while.
Finally, you can verify that the inference service is working correctly:
POST _inference/text_embedding/mxbai-embed-large-v1
{
"input": "It takes all the running you can do, to keep in the same place. If you want to get somewhere else, you must run at least twice as fast as that!"
}should produce output like this:
{
"text_embedding": [
{
"embedding": [
-0.028375082,
0.6544269,
0.1583663,
0.88167363,
0.5215657,
0.05415681,
0.62085253,
0.069351405,
0.29407632,
0.51018727,
0.8183201,
...
]
}
]
}Conclusion
By following the steps in this article, you can set up LocalAI to compute embeddings for your data using GPU acceleration without having to rely on third-party inference services. With LocalAI, users of Elasticsearch in air-gapped environments or with privacy concerns can leverage the world-class vector database for their RAG applications without sacrificing computational performance or the ability to select the best AI model for their needs.
Try building your own RAG application with Elastic Stack today: in the cloud, in the air-gapped environment or on your laptop!