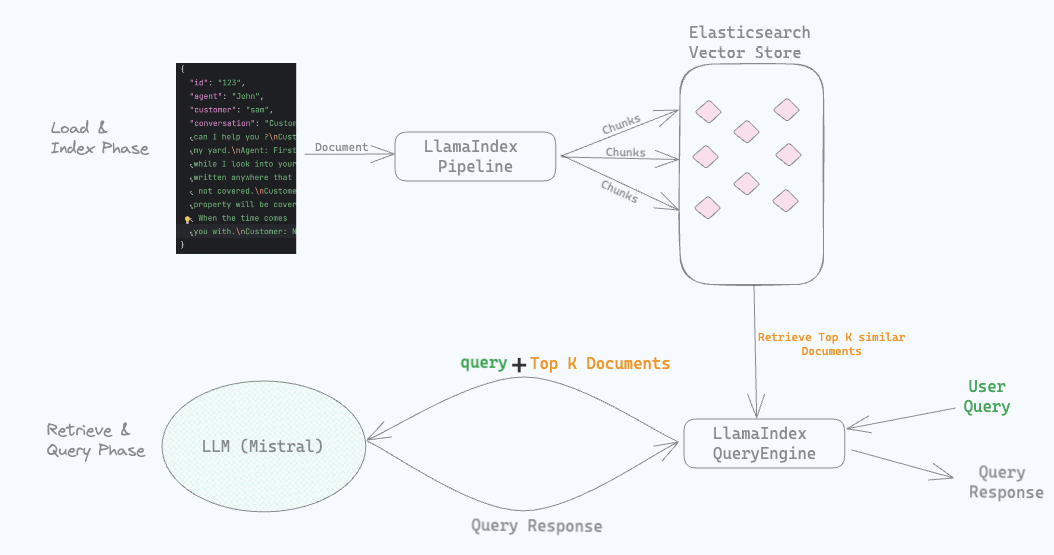
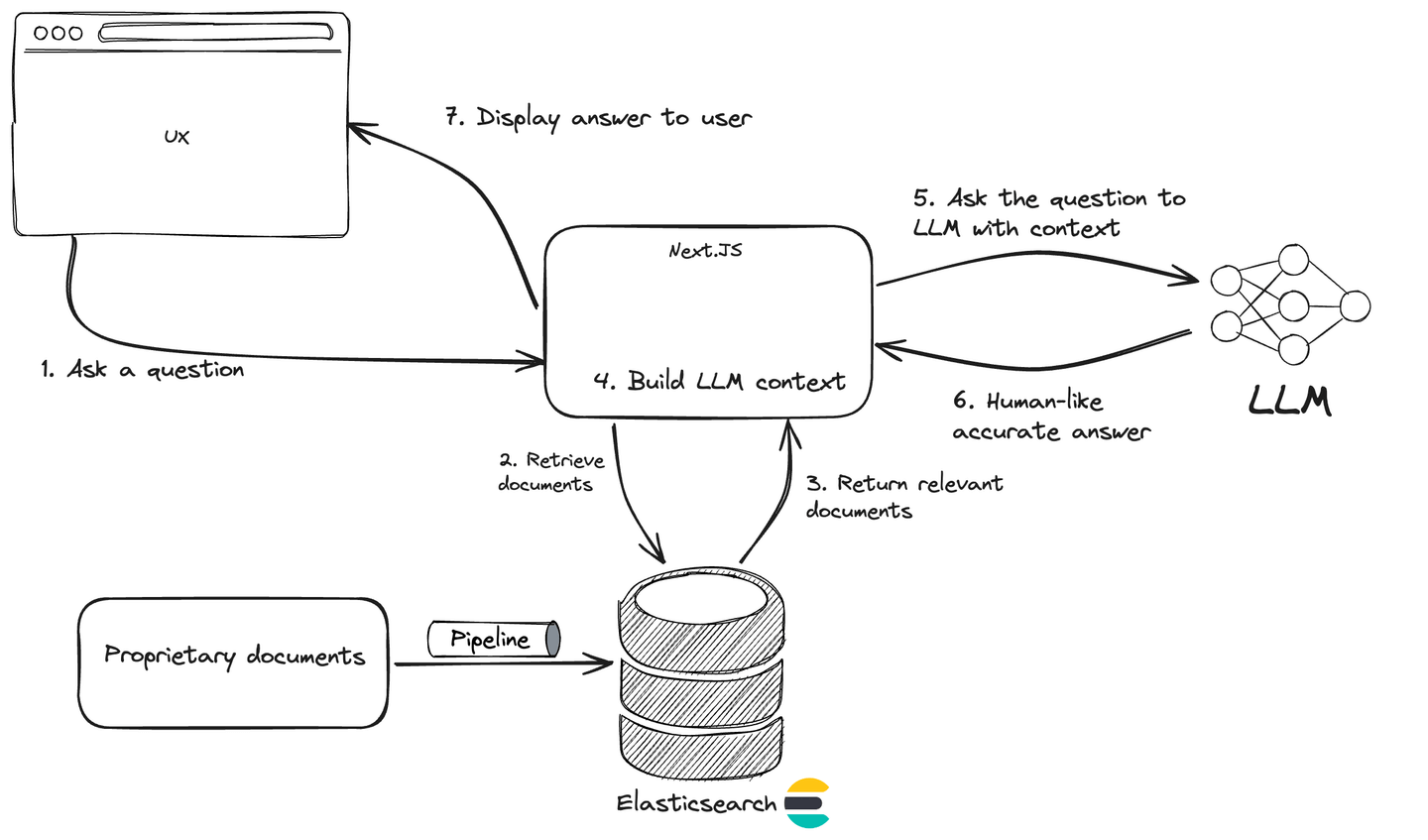
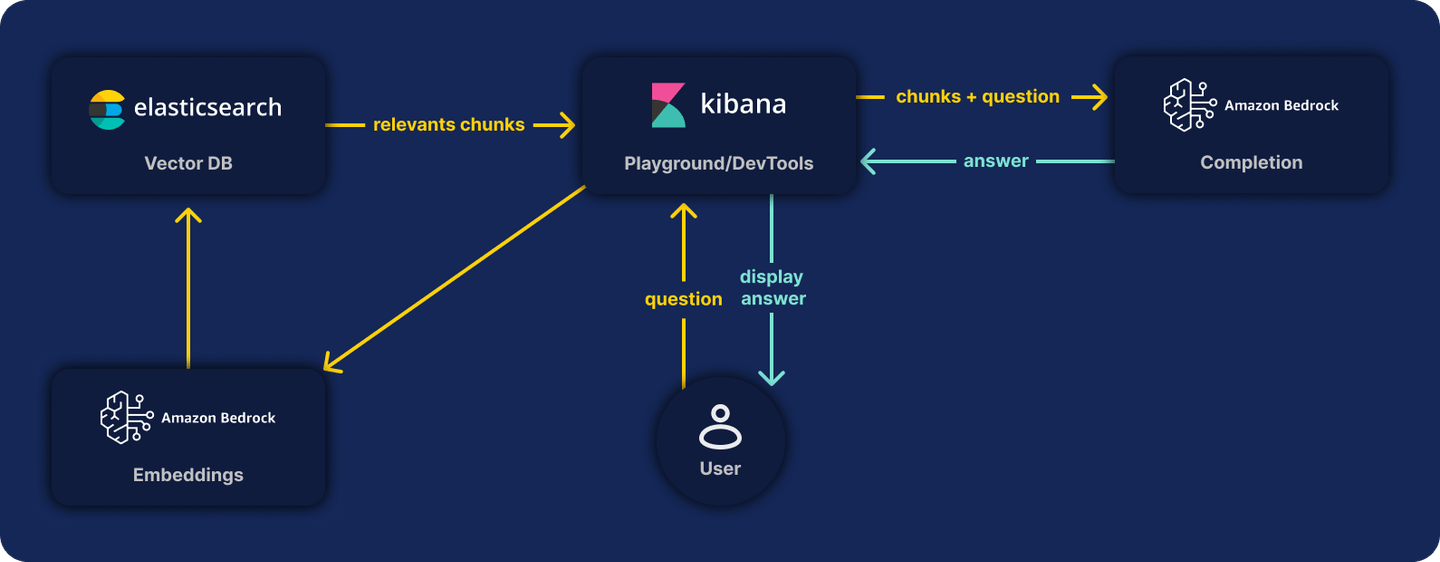
Introduction
Integrating Elasticsearch and NVIDIA NIM using advanced LLM models, significantly boosts applications with natural language processing capabilities. Built on NVIDIA's software stack, which includes CUDA and TensorRT, NVIDIA NIM offers features such as in-flight batching. This technique speeds up request processing by handling multiple iterations of execution simultaneously, while integrating seamlessly with Elasticsearch to enhance data indexing and search functionalities. Before we begin our main example of building a RAG (Retrieval Augmented Generation), use the section below to test the NVIDIA key required for the rest of the application.
NVIDIA NIM
To expedite the development of your application prototypes, consider using the NVIDIA NIM endpoints hosted in the cloud, which was designed to simplify and accelerate this process. At nvidia.ai, you can explore and experiment with various LLM models through API calls to the NVIDIA NIM microservices.
NVIDIA API key
To create a code to interact with NIM microservices, as in the example below, we utilize a API-KEY retrieved from the environment variable os.environ['NVIDIA_API_KEY']. To acquire this key, you must first establish a developer account on NVIDIA's platform. Once you have logged in, proceed to the designated webpage to obtain your API key. This process is visually detailed in the illustration below for your convenience. For details click here.
Using the assistant, you can copy and adjust the code, then run it in your environment as follows:
!pip install openai
from openai import OpenAI
client = OpenAI(
base_url = "https://integrate.api.nvidia.com/v1",
api_key = os.environ['NVIDIA_API_KEY']
)
completion = client.chat.completions.create(
model="google/codegemma-7b",
messages=[{"role":"user","content":
"Elasticsearch command to view the fields of the index 01-rio-meetup:\n\n"}],
temperature=0.5,
top_p=1,
max_tokens=1024,
stream=True
)
for chunk in completion:
if chunk.choices[0].delta.content is not None:
print(chunk.choices[0].delta.content, end="")Result:
GET 01-rio-meetup/_mapping
This command will return the field mappings for the "01-rio-meetup" index.
The response will show you all the fields in the index, along with
their data types and other metadata.In this way, we execute a call to the google/codegemma-7b LLM model within the framework of NVIDIA's cloud through the available microservice of NVIDIA NIM. It's that simple.
This was a straightforward step only using the NVIDIA API. Now we'll dive into how we can interact with Elasticsearch in a RAG application.
Integrating NVIDIA NIM with Elastic using LangChain: RAG example
What if we could combine the power of Elasticsearch's vector search to bring relevant information and send the context to an LLM call (running within NVIDIA's cloud), avoiding model hallucinations and using updated data from Elasticsearch? Then, let's set up our RAG.
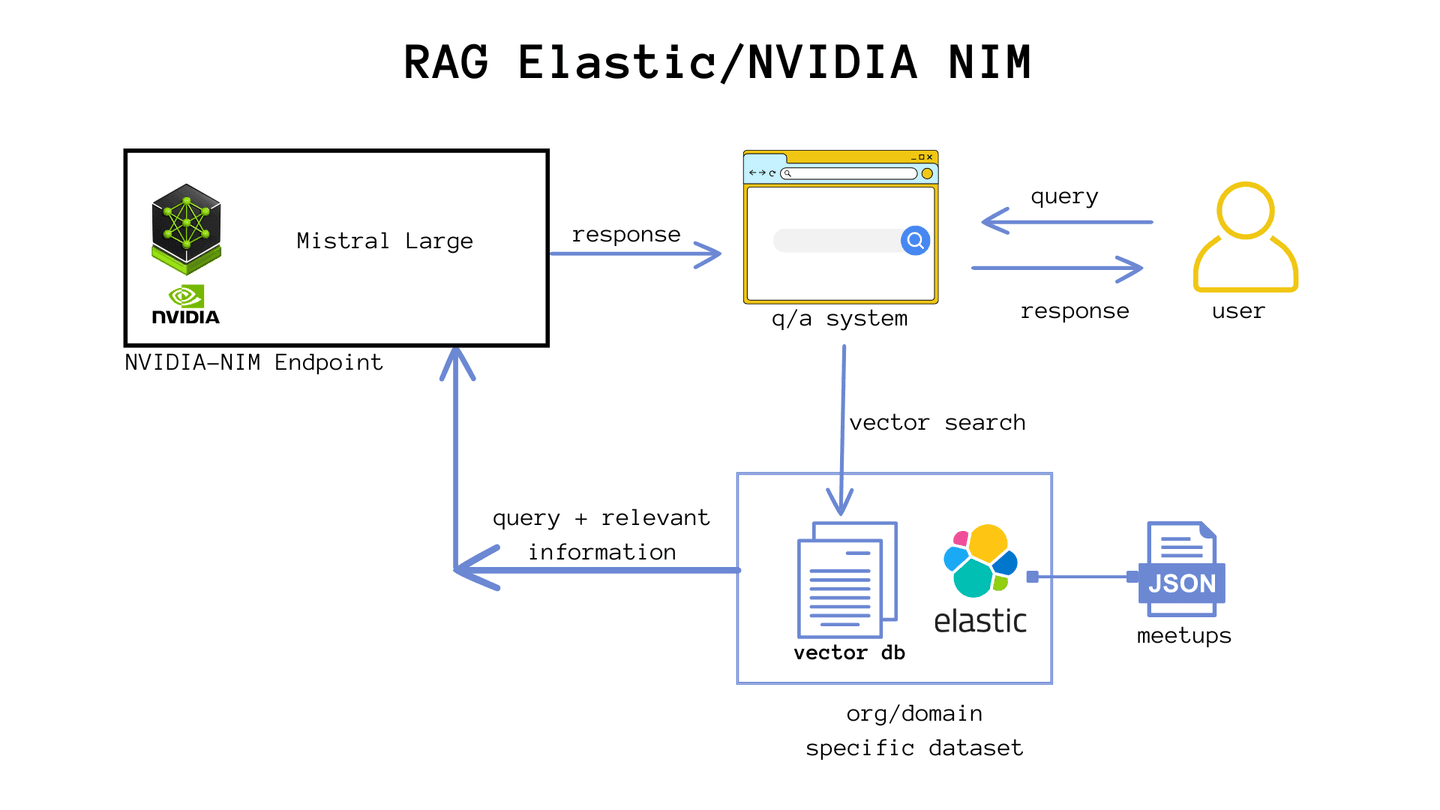
Creating a meetup calculator with NVIDIA NIM, Elasticsearch & GenAI
Organizing a successful technical meetup requires meticulous planning and attention to detail. One of the biggest challenges is ensuring that the event meets the needs and expectations of all participants, providing a valuable and memorable experience. With this example, we will show how the integration of Elasticsearch, NVIDIA NIM, and generative AI can help in organizing a flawless technical meetup, from gathering information to generating customized reports.
We will use Python in a Jupyter Notebook to demonstrate how to process and store registrations using Elasticsearch and NVIDIA NIM.
Initial setup
First, we set up our environment and install the necessary dependencies:
You will need:
- A Jupyter Notebook editor with Python, such as Google Colab.
- Access to Elasticsearch. This example uses Elasticsearch version 8.13; if you are new, check out our Quick Start on Elasticsearch.
- Create an ELASTIC_API_KEY within Kibana. Creating an API Key
- Create a Developer account on the NVIDIA website.
- Obtain the NVIDIA_API_KEY within the NVIDIA Catalog explorer.
Once this is done, create a new file in Jupyter Notebook and type the commands to install the necessary packages:
!pip install langchain_nvidia_ai_endpoints
!pip install langchain-community langchain-text-splitters langchain
!pip install -q -U langchain-elasticsearch python-dotenvNVIDIA provides an integration with LangChain through the langchain-nvidia-ai-endpoints package, which connects users to optimized artificial intelligence models, such as Mixtral 8x7B and Llama 2, available in the NGC catalog. With this, the models can be quickly customized and implemented with enterprise support through NVIDIA AI Enterprise. LangChain provides direct support for these models, enabling easy access and use in various applications, after the initial setup of an account in NGC and the installation of the package via pip.
Import the libraries.
Note: Here, we can see that we will make extensive use of LangChain.
from langchain_nvidia_ai_endpoints import NVIDIAEmbeddings, ChatNVIDIA
from langchain_elasticsearch import ElasticsearchStore
from langchain.text_splitter import CharacterTextSplitter
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from urllib.request import urlopen
import jsonEnvironment variables
We need to create some environment variables to store values of API keys and connections that we do not want to expose in the code.
Feel free to program in your own way. I used a file called env_ and placed it in my Google Drive for convenience. This way, I access the file (env_path = '/content/drive/MyDrive/@Blogs/05-NVIDIA-NIM/env_') which will set the values in the command load_dotenv(env_path).
Here is an example of the format of my env_ file:
CLOUD_PASS="your-elastic-password"
CLOUD_ID="your-elastic-cloud-id"
CLOUD_USER="elastic"
ELASTIC_API_KEY="your-key-value"
NVIDIA_API_KEY="your-key-value"
OPENAI_API_KEY="your-key-value"Following the code, we need to grant access to Google Drive to access the file that sets up the environment variables. For this, you must be logged into a Google account.
# Mount /content/drive
from google.colab import drive
drive.mount('/content/drive')Now we will access the file and configure the values.
import os
from dotenv import load_dotenv
# Replace 'path/to/your/.env' with the correct path to your .env file on Google Drive
env_path = '/content/drive/MyDrive/@Blogs/05-NVIDIA-NIM/env_'
load_dotenv(env_path)
# Elastic cloud credentials
es_cloud_id = os.getenv('CLOUD_ID')
es_user = os.getenv('CLOUD_USER')
es_pass = os.getenv('CLOUD_PASS')
ELASTIC_API_KEY = os.getenv('ELASTIC_API_KEY')Let's also set the name of the index that will be created in Elasticsearch. In our case, it will be a meetup in the city of Rio de Janeiro.
elastic_index_name = "01-rio-meetup"As mentioned earlier, to connect to NVIDIA NIM, you need the API key provided.
os.environ['NVIDIA_API_KEY'] = os.getenv('NVIDIA_API_KEY')There you go, all environment variables and keys are ready to be used.
Meetup scenario
Imagine a technical meetup with a maximum of 20 participants, held in the evening at a coworking space. After two talks, there will be a coffee break for networking. To meet everyone's needs, participants will be asked about dietary restrictions, mobility/accessibility difficulties, and beverage preferences (juice, water, beer, soda) during registration.
We could store participant information in Elasticsearch as registrations are made in a registration system, but in our example, we will get this data from a JSON file.
# Download the dataset
url = "https://raw.githubusercontent.com/salgado/public-dataset/main/meetup-participants.json"
response = urlopen(url)
workplace_docs = json.loads(response.read())Split Documents into Passages (Chunking)
metadata = []
content = []
for doc in workplace_docs:
content.append(doc["observation"])
metadata.append(
{
"name": doc["name"],
"observation": doc["observation"]
}
)
text_splitter = CharacterTextSplitter(chunk_size=50, chunk_overlap=0)
docs = text_splitter.create_documents(content, metadatas=metadata)Set embeddings of the chunks using Langchain predefine NVIDIA functions
query_embedding = NVIDIAEmbeddings()The query_embedding object created by NVIDIAEmbeddings() is used to convert text into numerical vectors (generation of embeddings). These vectors are then used for operations such as semantic searches.
Store in Elasticsearch vector database
es = ElasticsearchStore.from_documents(
docs,
es_cloud_id=es_cloud_id,
es_api_key=ELASTIC_API_KEY,
index_name=elastic_index_name,
embedding=query_embedding,
)Let's create a retriever to collect data from event participants.
- Note: Remember that, to simplify, this index stores data for only 1 event.
retriever = es.as_retriever(search_kwargs={"k": 20})Using a model from NVIDIA NIM microservices
One of the great advantages for developers when using NVIDIA NIM microservices is the ease of selecting from various available and scalable models, all in a single line of code.
model = ChatNVIDIA(model="mistral_7b")In the example we presented, we used the LLM model mistral_7b, developed by Mistral AI. This model is part of a set of over a dozen popular AI models supported by NVIDIA NIM microservices. The list includes models like Mixtral 8x7B, Llama 70B, Stable Video Diffusion, Code Llama 70B, Kosmos-2, among others. The NIM platform is designed to simplify the deployment of NVIDIA AI Foundation models and custom models.
Creating a RAG with Elastic using LangChain
To answer questions about participants, we employed the RAG architecture, with relevant information stored in the Elasticsearch index and dense content in the vector field extracted from participant observation data.
Response chain execution
Now we are ready to ask the model to help us with organizing the meetup.
template = """Answer the question based only on the following context:\n
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)The code snippet presented defines a template to generate chat prompts, using placeholders to insert specific contexts and questions. The template variable stores a string that guides the response of a natural language model based solely on the provided context and question. This structure is converted into a ChatPromptTemplate object through the from_template function, allowing for dynamic creation of formatted prompts that guide the model's responses in a relevant and focused manner, facilitating precise interactions in applications using natural language processing.
chain = (
{"context": retriever , "question": RunnablePassthrough()}
| prompt
| model
| StrOutputParser()
)Here, we set up a pipeline or transformation chain that starts with the retrieval prompt, contextualizing with data from Elasticsearch through the Reporting Observer object, passes through the LLM model, and ends with an output parser that converts the model's output into plain text. This chain is crucial for processing the question and generating the response in a readable format. This code snippet sets up a data processing pipeline to handle chat interactions, particularly in the context of integration with NVIDIA. Let's break down each part:
{"context": retriever , "question": RunnablePassthrough()}: Here, we define the initial structure of the pipeline.retrieveris a variable representing the context that will be provided to the language model.RunnablePassthrough()is an object representing the question that will be asked to the model. In other words, this initial part of the pipeline prepares the context and question to be sent to the language model.| prompt: This part of the code applies thepromptobject, created from a template, to generate a formatted chat prompt based on the provided context and question. The generated prompt guides the language model to produce a relevant response.| model: Here, the pipeline sends the formatted prompt to the language model, which processes the input and generates a response based on the provided information.| StrOutputParser(): Finally,StrOutputParser()is used to process the output from the language model and format it as needed before presenting it as the final result. This may include text formatting, filtering out irrelevant information, among other adjustments.
prompt = """Generate a menu of food and drink to be served, respecting dietary restrictions.\n
Generate a single order that can be placed on a food and drink delivery website.
We will buy spicy sausage pizza, vegan pizza, and gluten-free Margherita pizza.
For drinks, we will have Coca-Cola, water, beer, and grape juice.
Calculate the quantity of the order so that each guest can eat 3 slices of pizza and drink 500ml of beverage.
1 pizza contains 8 slices.
Finally, Estimate the cost of this purchase based on average prices in the city of Rio de Janeiro.
"""
for s in chain.stream(prompt):
print(s, end="")Finally, we define a specific question related to event planning and invoke the chain with this question. The system uses the RAG model to retrieve relevant information and generate a response, which is then printed.
To ensure we cater to all dietary restrictions, let's create a menu from the given context:
1. Spicy Sausage Pizza: For guests with no dietary restrictions (Arrow, Thor, Wonder Woman, Green Lantern)
2. Vegan Pizza: For vegetarian guests (Black Widow, Flash, Daredevil, Cyborg, Hulk, Captain America, Black Panther, Doctor Strange)
3. Gluten-Free Margherita Pizza: For guests with gluten-free requirements (Deadpool)
For drinks, we will have:
1. Coca-Cola: For guests who drink soda (Arrow, Superman)
2. Water: For guests with no dietary restrictions or specific beverage requirements (Black Widow, Flash, Daredevil, Cyborg, Hulk, Captain America, Black Panther, Doctor Strange, Deadpool, Spider-Man, Batman, Iron Man)
3. Juice: For guests who prefer juice (Black Widow, Flash, Hulk, Wolverine, Aquaman)
4. Beer: For guests who drink beer (Thor, Wonder Woman, Green Lantern, Batman, Iron Man)
To calculate the quantity of the order, we need to find out how many guests there are in total and how many slices of pizza and 500ml of beverage each guest will consume:
Total number of guests = 15
Pizza slices per guest = 3
Total pizza slices needed = 15 * 3 = 45 slices
Pizza boxes usually contain 8 slices, so we need to buy 6 boxes
Total beverages per guest = 500ml
Total beverage volume needed = 15 * 500ml = 7500ml
Now let's estimate the cost of this purchase based on average prices in Rio de Janeiro:
1. Pizza:
- Spicy Sausage Pizza: R$ 25 per box
- Vegan Pizza: R$ 22 per box
- Gluten-Free Margherita Pizza: R$ 28 per box
2. Drinks:
- Coca-Cola: R$ 3.50 per bottle (750ml)
- Water: R$ 1.50 per bottle (500ml)
- Juice: R$ 4.50 per bottle (500ml)
- Beer: R$ 7 per can (355ml)
Total cost for 15 guests:
- Pizza: 6 boxes * (Spicy Sausage, Vegan, Gluten-Free) = R$ 150 + R$ 132 + R$ 176 = R$ 458
- Drinks:
- Coca-Cola: 5 guests * 3 bottles = R$ 45
- Water: 10 guests * 3 bottles = R$ 90
- Juice: 5 guests * 3 bottles = R$ 75
- Beer: 5 guests * 3 cans = R$ 75
Total cost: R$ 613
So the total cost for this order would be R$ 613.We could then ask other questions using the same chain, for example:
prompt = """
How many guests have dietary restrictions and what are they?
"""
for s in chain.stream(prompt):
print(s, end="")Based on the context provided, there are a total of 15 guests with dietary restrictions. Here's a breakdown of their restrictions:
1. Cyborg: Strict vegetarian
2. Daredevil: Vegetarian
3. Deadpool: Low fat
4. Hulk: Vegetarian, gluten-free
5. Wolverine: Vegetarian, sugar-free
6. Mystique: Allergic to seafood
7. Flash: Vegan
8. Black Widow: None
9. Spider-Man: Lactose intolerant
10. Black Panther: Celiac
11. Aquaman: Vegan, allergic to soy
12. Doctor Strange: None
13. Batman: Allergic to nuts
14. Captain America: Diabetic
15. Arrow: None (but needs ramp)Note 1: It is recommended to explore the use of other models and consider fine-tuning and other advanced techniques that go beyond the scope of this blog.
Note 2: Accordingly with GOVERNING TERMS: Your use of NVIDIA NIM API is governed by the NVIDIA API Trial Service Terms of Use; and the use of this model is governed by the NVIDIA AI Foundation Models Community License and Mistral AI Terms of Use.
Conclusion
The integration of NVIDIA NIM with Elasticsearch allows users to leverage real-time analytics and complex search capabilities efficiently. By combining NVIDIA's LLM architectures with Elasticsearch's flexible and scalable search engine, organizations can achieve more responsive insights and search experiences. NVIDIA NIM's microservices architecture effortlessly scales to meet diverse demands and supports a wide range of applications, from enhancing chatbots with nuanced language understanding to providing real-time sentiment analysis and accurate language translation. To access these functionalities, we used the LangChain framework that integrates with NVIDIA NIM's microservices and Elasticsearch. All examples can be replicated for free (using trial versions) and by using the API keys shown in this blog. The complete Python notebook showcasing all the above implementations can be found on the elasticsearch-labs repository.
What would you change to meet your needs?