Parsing documents before making information searchable is an important step in building real-world RAG applications. Unstructured.io and Elasticsearch work effectively together in this scenario, providing developers with complementary tools to build RAG applications.
Unstructured.io provides a library of tools to extract, clean, and transform documents in different formats and from different content sources. Once documents are added to Elasticsearch indices, developers can choose from a number of Elastic features including aggregations, filters, RBAC tools, and BM25 or vector search capabilities — to implement complex business logic into RAG applications.
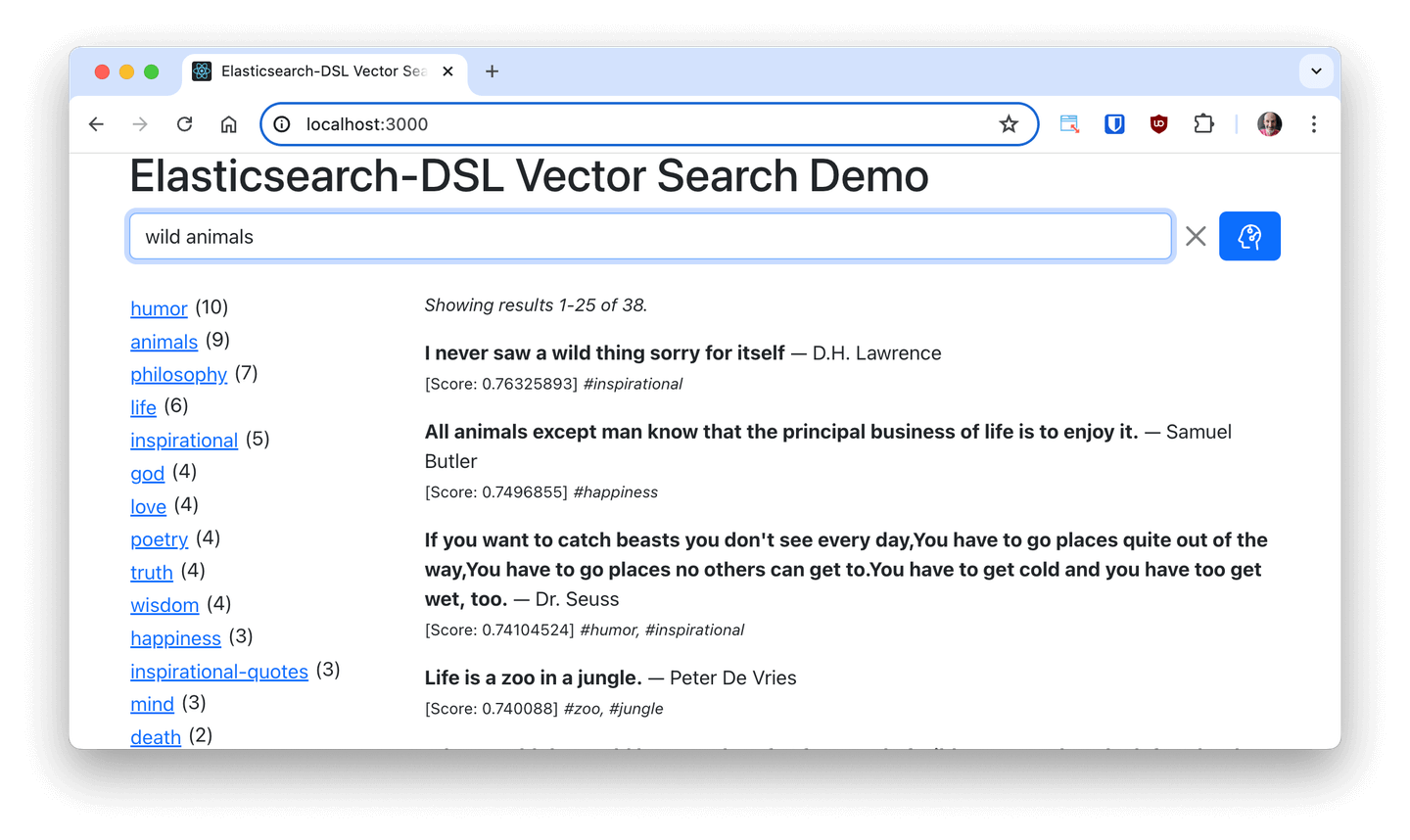
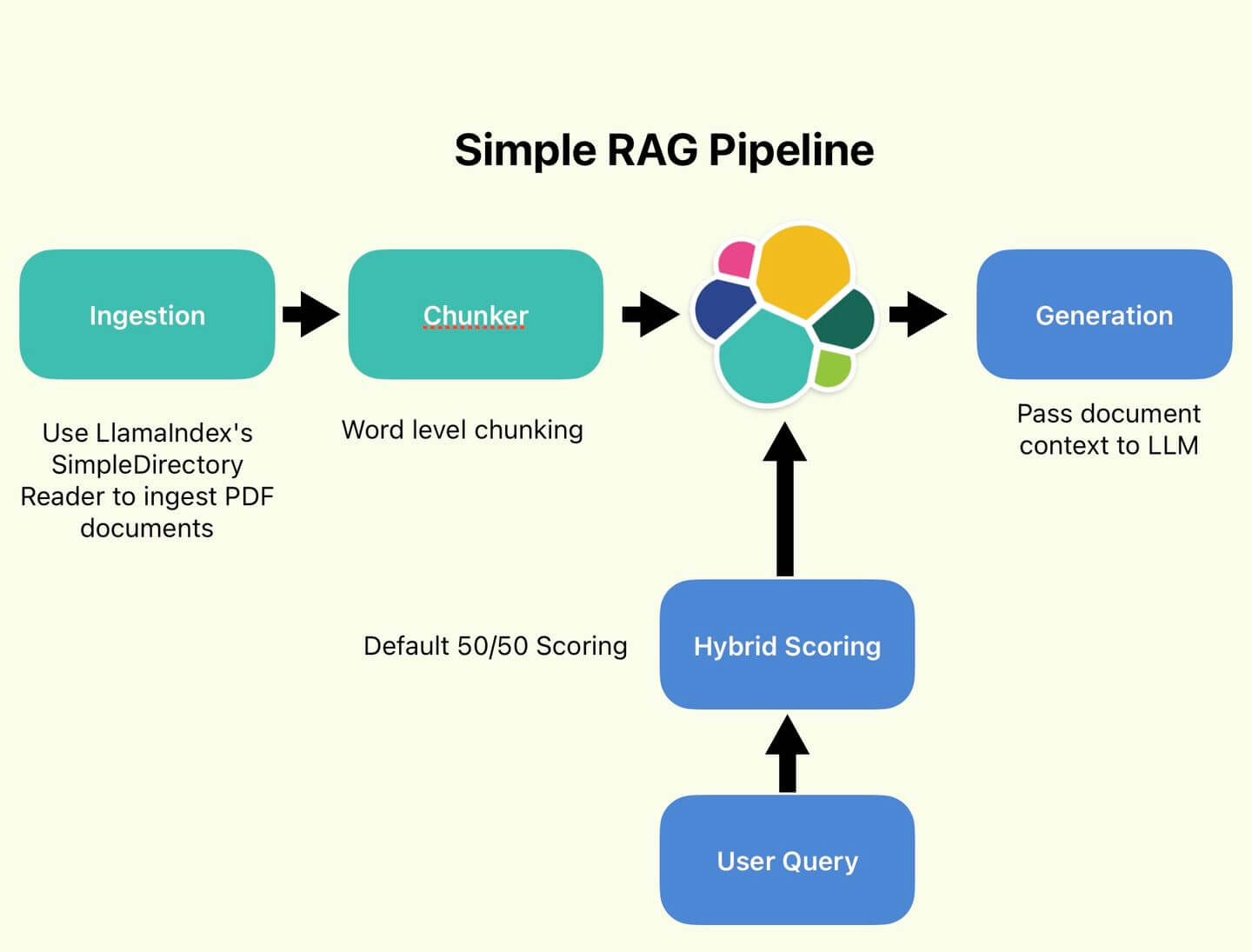
In this blog, we will examine a fairly common use case, which is parsing and ingesting a PDF document that contains text, tables, and images. We will create sparse vector embeddings using Elastic’s ELSER model, then store and search embeddings using Elastisearch as a vector database.
Unstructured’s power is in models that can recognize unique components of a document and extract them into “document elements.” Unstructured also has the ability to chunk partitions using different strategies instead of just by the number of characters. These “smart partitioning and chunking” strategies can improve search relevance and reduce hallucinations in a RAG application.
After parsing data, we store it as vector embeddings in the Elasticsearch vector database and run search operations. We use the Elasticsearch vector database connector to send this data to Elastic. We also attached a pipeline to the flow so that ELSER, an out-of-the-box sparse encoder model for semantic search, embeddings are created upon ingest.
How to parse and search unstructured documents
- Deploy the ELSER model in the Elastic platform,
- Create an ingest pipeline that will create embeddings for the ingested chunks. The field
textwill store the chunked text and thetext_embeddingswill store the embeddings. We will use the ELSER v2 model.
PUT _ingest/pipeline/chunks-to-elser
{
"processors": [
{
"inference": {
"model_id": ".elser_model_2_linux-x86_64",
"input_output": [
{
"input_field": "text",
"output_field": "text_embedding"
}
]
}
}
]
}- The next step is to create an index,
unstructured-demo, with the necessary mapping for the ELSER embeddings. We’ll also attach the pipeline we created in the previous step to this index. We will allow all the other fields to be dynamically mapped.
PUT unstructured-demo
{
"settings": {
"default_pipeline": "chunks-to-elser"
},
"mappings": {
"properties": {
"text_embedding": {
"type": "sparse_vector"
},
"text": {
"type": "text"
}
}
}
}- The final step is to run Unstructured’s code example using the Elasticsearch connector to create the partitions and chunks. Follow the instructions to install the dependencies.
import os
from unstructured.ingest.connector.elasticsearch import (
ElasticsearchAccessConfig,
ElasticsearchWriteConfig,
SimpleElasticsearchConfig,
)
from unstructured.ingest.connector.local import SimpleLocalConfig
from unstructured.ingest.interfaces import (
ChunkingConfig,
PartitionConfig,
ProcessorConfig,
ReadConfig,
)
from unstructured.ingest.runner import LocalRunner
from unstructured.ingest.runner.writers.base_writer import Writer
from unstructured.ingest.runner.writers.elasticsearch import (
ElasticsearchWriter,
)We set the host to be an Elastic Cloud (Elasticsearch service). We set a username and password and set the index we’re writing to:
def get_writer() -> Writer:
return ElasticsearchWriter(
connector_config=SimpleElasticsearchConfig(
access_config=ElasticsearchAccessConfig(
hosts="https://unstructured-demo.es.us-central1.gcp.cloud.es.io",
username="elastic",
password=<insert password>
),
index_name="unstructured-demo",
),
write_config=ElasticsearchWriteConfig(
batch_size_bytes=15_000_000,
num_processes=2,
),
)For this next step, sign up for an Unstructured API endpoint and key. Partitioning functions in Unstructured extract structured content from unstructured documents. partition function detects the document type and automatically determines the appropriate partition function. If the users know their file types, they can also specify the specific partition function.
In the partition step, we instruct Unstructured to infer table structures by passing in pdf_infer_table_structure=True and setting the partition strategy to hi_res, automatically identifying the document's layout. You can learn about various Unstructured Partitioning Strategies here. We set the chunking strategy to by_title, which “preserves section and page boundaries”. Chunking strategy has a significant impact on the performance and quality for your RAG applications. You can learn more about Unstructured work on this in their Chunking for Effective Retrieval Augmented Generation paper.
writer = get_writer()
runner = LocalRunner(
processor_config=ProcessorConfig(
verbose=True,
output_dir="local-output-to-elasticsearch",
num_processes=2,
),
connector_config=SimpleLocalConfig(
input_path=<path to PDF>,
),
read_config=ReadConfig(),
partition_config=PartitionConfig(pdf_infer_table_structure=True,strategy='hi_res',partition_by_api=True, partition_endpoint=<your partition endpoint>', api_key=<your api key>),
chunking_config=ChunkingConfig(chunk_elements=True, max_characters=500, chunking_strategy="by_title"),
writer=writer,
writer_kwargs={},
)
runner.run()In the resulting documents in the Elasticsearch vector database, you will see some interesting metadata generated by the Unstructured API. If the element is a table, you will see the HTML structure of the table as well as information about its appearance. If it’s a chunk of text and a continuation of an earlier chunk, you will see is_continuation, which is valuable in RAG scenario when you want to pass the entire context of a paragraph to the LLM. If you want to know what individual partitions comprise a chunk, you can find it in the base-64 encoded orig_elements field.
In the example above, we used Unstructured’s API services. These API services can be used in three different ways:
- Limited trial Unstructured API
- SaaS Unstructured API
- AWS/Azure Marketplace Unstructured API
The trial offering processing capability is capped at 1000 pages, and your documents can be used for proprietary mode training and evaluation purposes. For quick prototyping, you could also look at Unstructured’s open-source version. The unstructured library provides you options to run using its Python installer. If you want to avoid dealing with several dependencies, you could use the Docker container that comes bundled with all the required libraries. The Unstructured API offers the following additional features compared to the open-source version:
- Significantly improved performance for document and table extraction, with advanced chunking and improved transformation pipelines
- Access to the latest vision transformer models and enterprise capabilities such as security, SOC2 compliance, IAM (Authentication and identity management)
Conclusion
Effective document parsing is an important step in building an effective RAG solution. Unstructured’s approach to transforming raw documents into data that LLMs can understand, coupled with Elastic’s strength as a vector database and search platform, will accelerate your journey to building with AI. Happy searching!