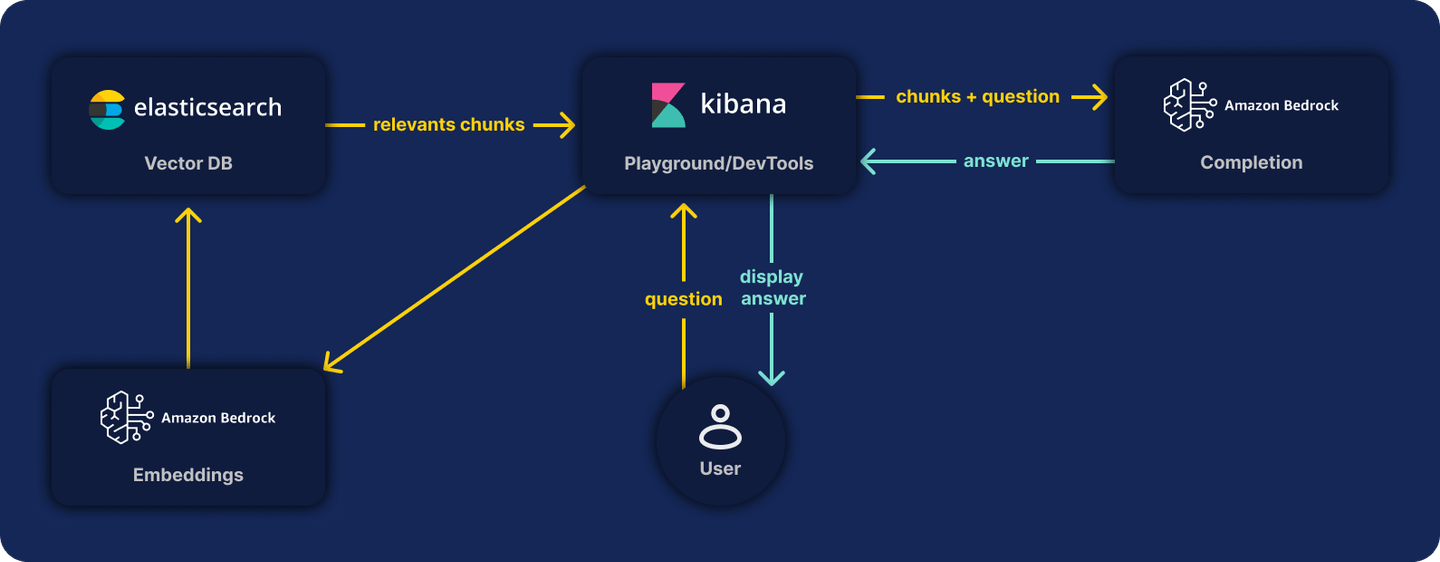
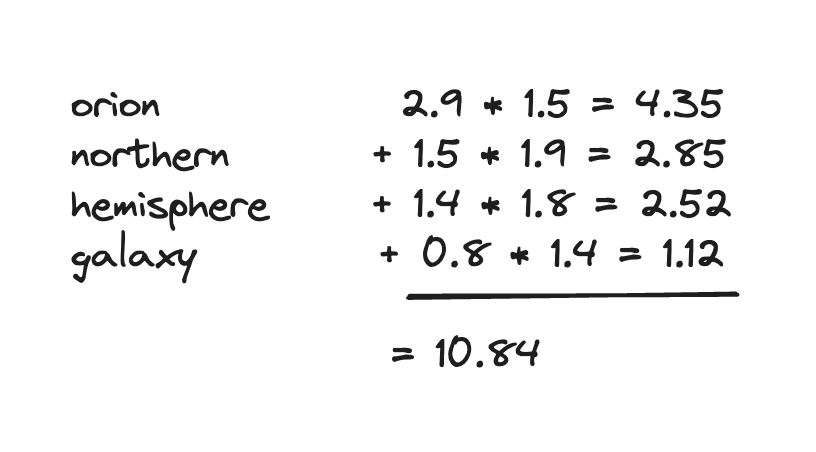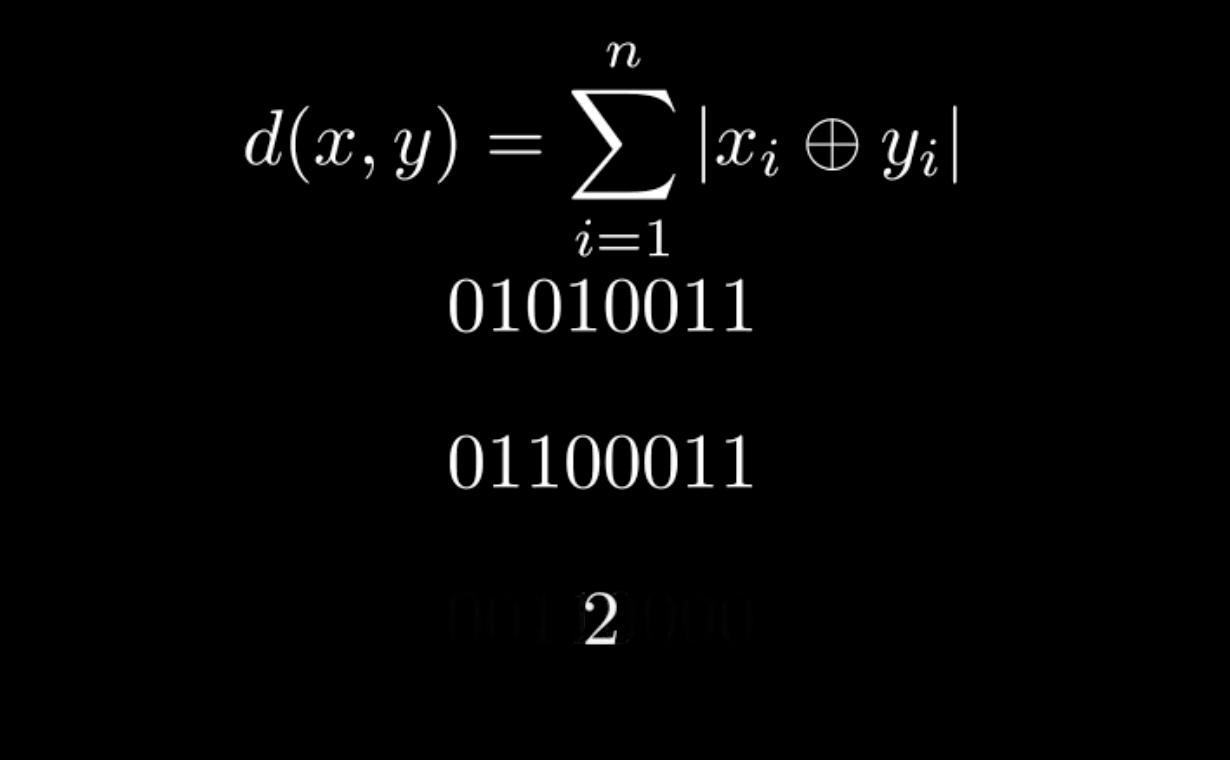Vector search is a powerful tool in the information retrieval tool box. Using vectors alongside lexical search like BM25 is quickly becoming commonplace. But there are still a few pain points within vector search that need to be addressed. A major one is text embedding models and handling larger text input.
Where lexical search like BM25 is already designed for long documents, text embedding models are not. All embedding models have limitations on the number of tokens they can embed. So, for longer text input it must be chunked into passages shorter than the model’s limit. Now instead of having one document with all its metadata, you have multiple passages and embeddings. And if you want to preserve your metadata, it must be added to every new document.
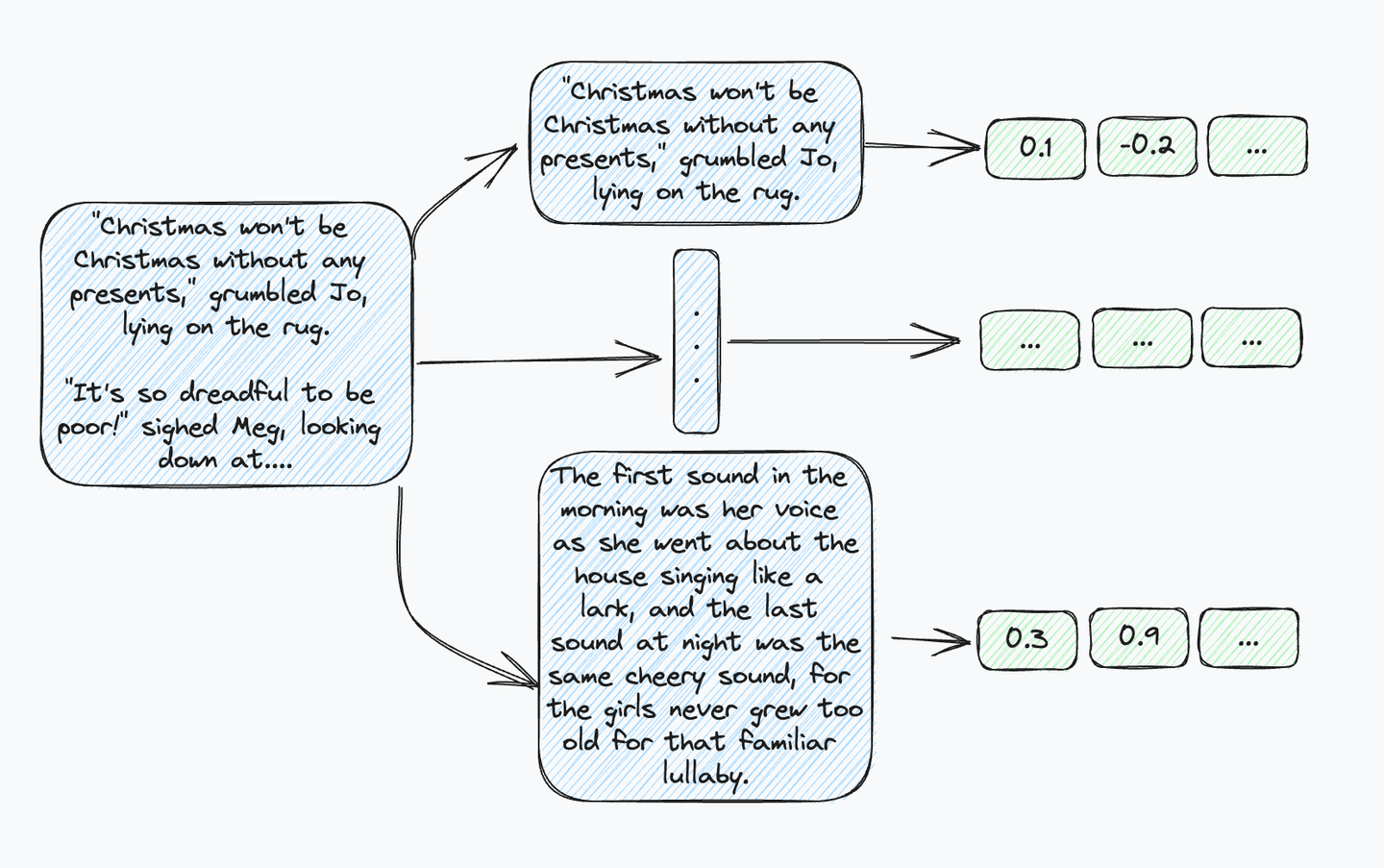
Figure 1: Now instead of having a single piece of metadata indicating the first chapter of Little Women, you have to index that information data for every sentence.
A way to address this is with Lucene's “join” functionality. This is an integral part of Elasticsearch’s nested field type. It makes it possible to have a top-level document with multiple nested documents, allowing you to search over nested documents and join back against their parent documents. This sounds perfect for multiple passages and vectors belonging to a single top-level document! This is all awesome! But, wait, Elasticsearch® doesn’t support vectors in nested fields. Why not, and what needs to change?
The (kNN) problem with parents and children
The key issue is how Lucene can join back to the parent documents when searching child vector passages. Like with kNN pre-filtering versus post-filtering, when the joining occurs determines the result quality and quantity. If a user searches for the top four nearest parent documents (not passages) to a query vector, they usually expect four documents. But what if they are searching over child vector passages and all four of the nearest vectors are from the same parent document? This would end up returning just one parent document, which would be surprising. This same kind of issue occurs with post-filtering.

Figure 2: Documents 3, 5, 10 are parent docs. 1, 2 belong to 3; 4 to 5; 6, 7, 8, 9 to 10.
Let us search with query vector A, and the four nearest passage vectors are 6, 7, 8, 9. With “post-joining,” you only end up retrieving parent document 10.
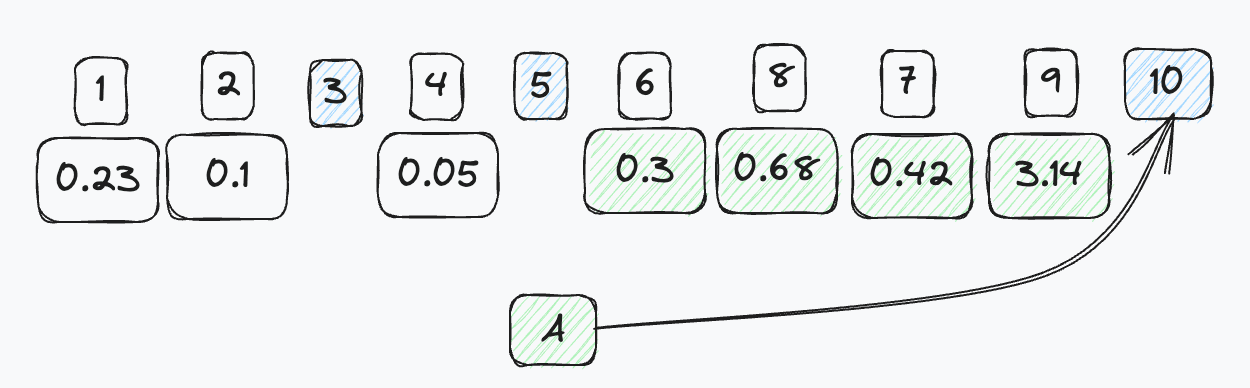
Figure 3: Vector “A” matching nearest all the children of 10.
What can we do about this problem? One answer could be, “Just increase the number of vectors returned!” However, at scale, this is untenable. What if every parent has at least 100 children and you want the top 1,000 nearest neighbors? That means you have to search for at least 100,000 children! This gets out of hand quickly. So, what’s another solution?
Pre-joining to the rescue
The solution to the “post-joining” problem is “pre-joining.” Recently added changes to Lucene enable joining against the parent document while searching the HNSW graph! Like with kNN pre-filtering, this ensures that when asked to find the k nearest neighbors of a query vector, we can return not the k nearest passages as represented by dense vectors, but k nearest documents, as represented by their child passages that are most similar to the query vector. What does this actually look like in practice?
Let’s assume we are searching the same nested documents as before:
Figure 4: Documents 3, 5, 10 are parent docs. 1,2 belong to 3; 4 to 5; 6, 7, 8, 9 to 10.
As we search and score documents, instead of tracking children, we track the parent documents and update their scores. Figure 5 shows a simple flow. For each child document visited, we get its score and then track it by its parent document ID. This way, as we search and score the vectors we only gather the parent IDs. This ensures diversification of results with no added complexity to the HNSW algorithm using already existing and powerful tools within Lucene. All this with only a single additional bit of memory required per vector stored.
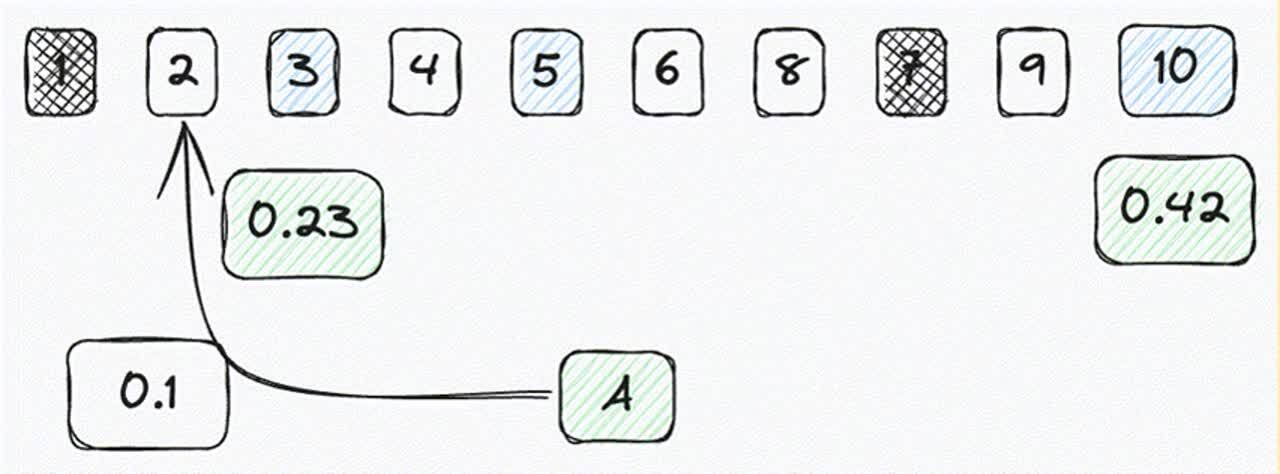
Figure 5: As we search the vectors, we score and collect the associated parent document. Only updating the score if it is more competitive than the previous.
But, how is this efficient? Glad you asked! There are certain restrictions that provide some really nice short cuts. As you can tell from the previous examples, all parent document IDs are larger than child IDs. Additionally, parent documents do not contain vectors themselves, meaning children and parents are purely disjoint sets. This affords some nice optimizations via bit sets. A bit set provides an exceptionally fast structure for “tell me the next bit that is set.” For any child document, we can ask the bit set, “Hey, what's the number that is larger than me that is in the set?” Since the sets are disjoint, we know the next bit that is set is the parent document ID.
Conclusion
In this post, we explored both the challenges of supporting dense document retrieval at scale and our proposed solution using nested fields and joins in Lucene. This work in Lucene paves the way to more naturally storing and searching dense vectors of passages from long text in documents and an overall improvement in document modeling for vector search in Elasticsearch. This is a very exciting step forward for vector search in Elasticsearch!
If you want to chat about this or anything else related to vector search in Elasticsearch, come join us in our Discuss forum.
The release and timing of any features or functionality described in this post remain at Elastic's sole discretion. Any features or functionality not currently available may not be delivered on time or at all.
In this blog post, we may have used or referred to third party generative AI tools, which are owned and operated by their respective owners. Elastic does not have any control over the third party tools and we have no responsibility or liability for their content, operation or use, nor for any loss or damage that may arise from your use of such tools. Please exercise caution when using AI tools with personal, sensitive or confidential information. Any data you submit may be used for AI training or other purposes. There is no guarantee that information you provide will be kept secure or confidential. You should familiarize yourself with the privacy practices and terms of use of any generative AI tools prior to use.
Elastic, Elasticsearch, ESRE, Elasticsearch Relevance Engine and associated marks are trademarks, logos or registered trademarks of Elasticsearch N.V. in the United States and other countries. All other company and product names are trademarks, logos or registered trademarks of their respective owners.