Vector Database

Smokin' fast BBQ with hardware accelerated SIMD instructions
How we optimized vector comparisons in BBQ with hardware accelerated SIMD (Single Instruction Multiple Data) instructions.
Using Eland on Elasticsearch Serverless
Learn how to use Eland on Elasticsearch Serverless
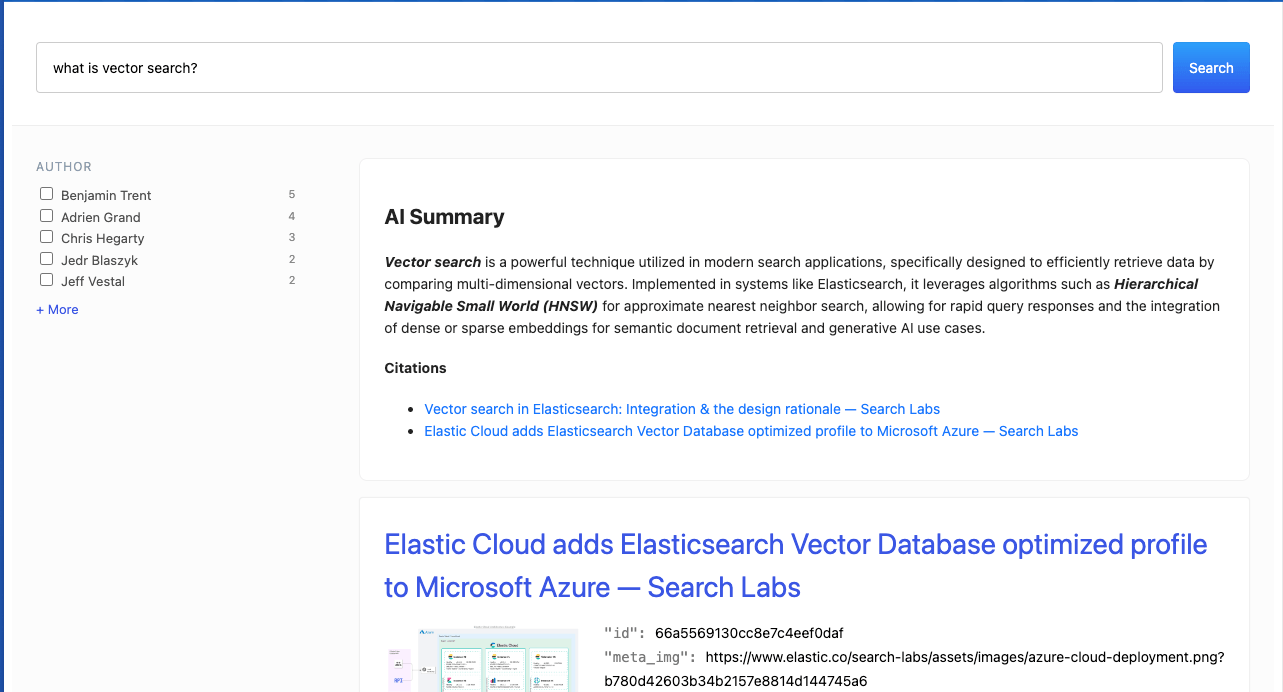
Adding AI summaries to your site with Elastic
How to add an AI summary box along with the search results to enrich your search experience.

Elasticsearch open Inference API adds support for AlibabaCloud AI Search
Discover how to use Elasticsearch vector database with AlibabaCloud AI Search, which offers inference, reranking, and embedding capabilities.

Understanding BSI IT Grundschutz: A recipe for GenAI powered search on your (private) PDF treasure
An easy approach to create embeddings for and apply semantic GenAI powered search (RAG) to documents as part of the BSI IT Grundschutz using Elastic's new semantic_text field type and the Playground in Elastic.
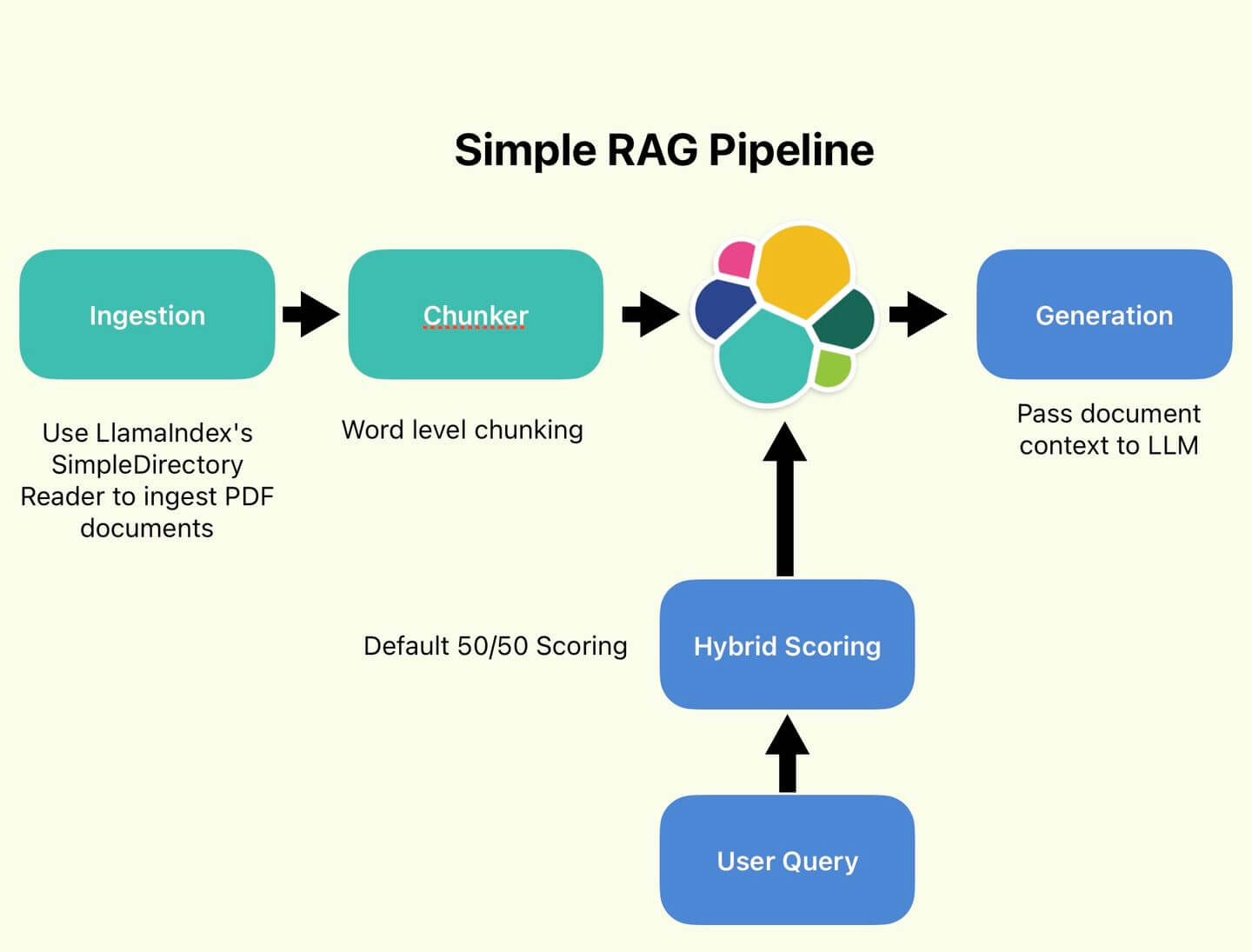
Advanced RAG Techniques Part 2: Querying and Testing
Discussing and implementing techniques which may increase RAG performance. Part 2 of 2, focusing on querying and testing an advanced RAG pipeline.
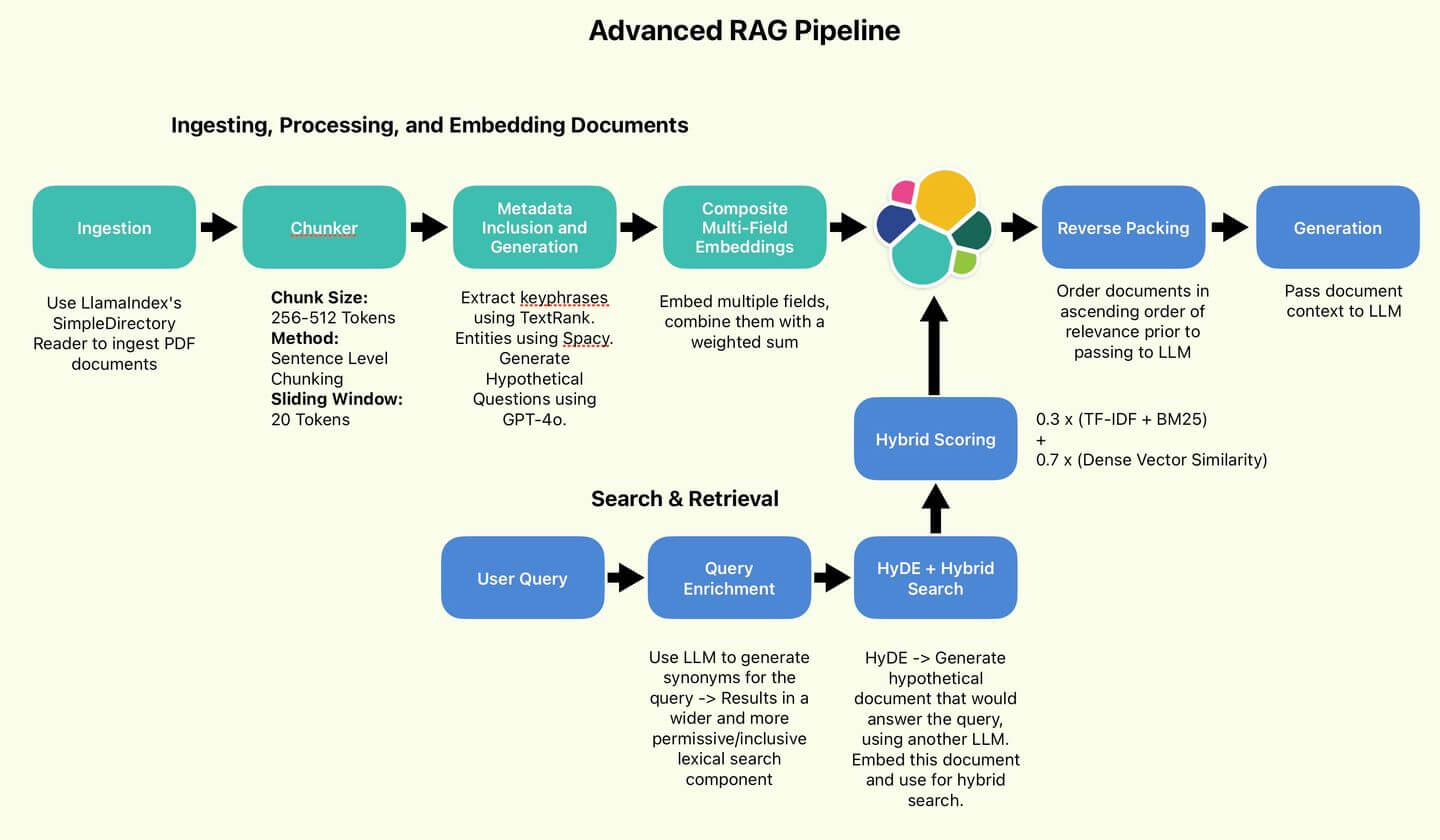
Advanced RAG Techniques Part 1: Data Processing
Discussing and implementing techniques which may increase RAG performance. Part 1 of 2, focusing on the data processing and ingestion component of an advanced RAG pipeline.
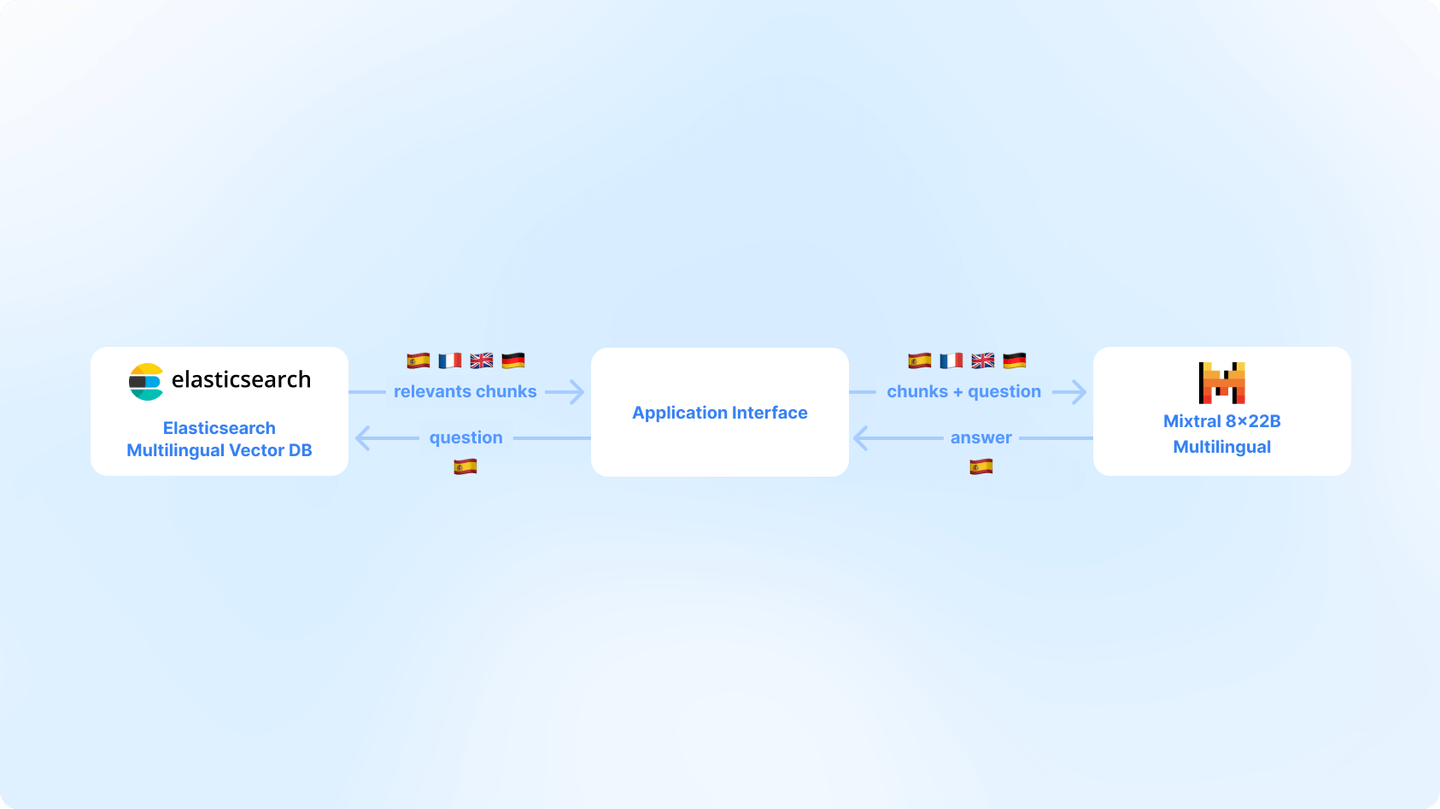
Building multilingual RAG with Elastic and Mistral
Building a multilingual RAG application using Elastic and Mixtral 8x22B model
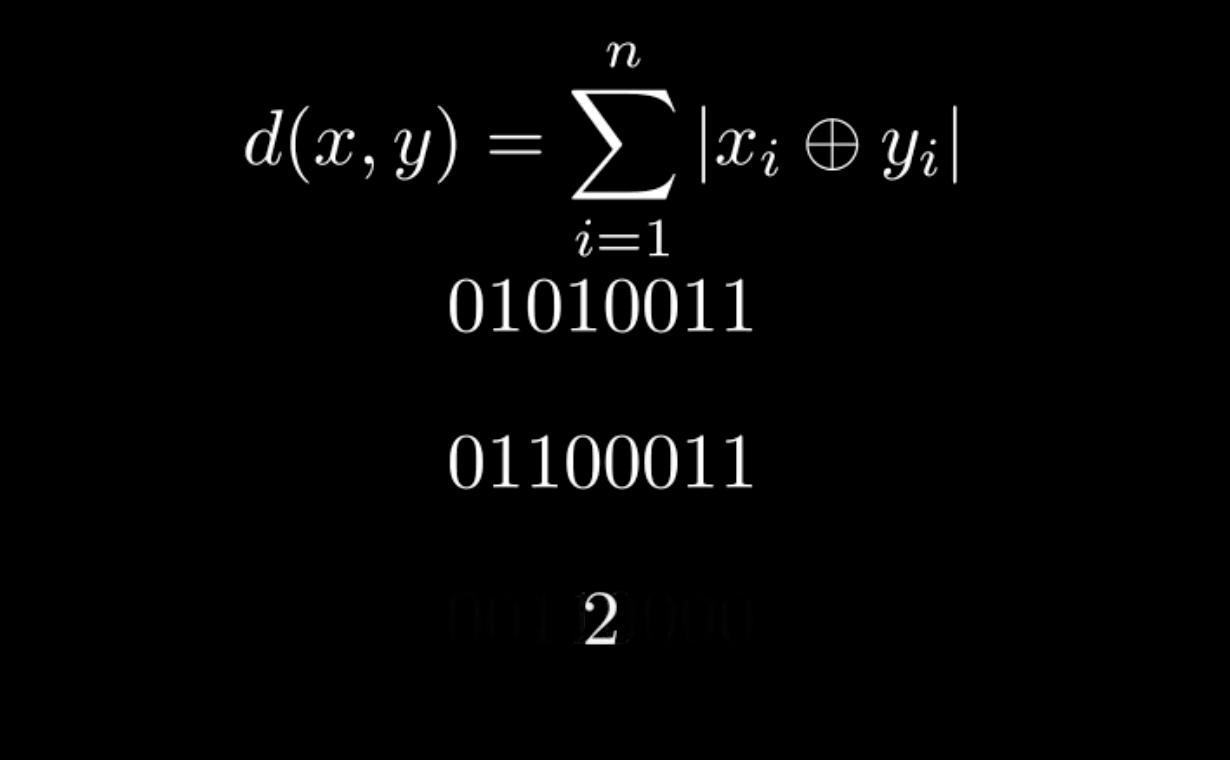
Bit vectors in Elasticsearch
Discover what are bit vectors, their practical implications and how to use them in Elasticsearch.

Elasticsearch open inference API adds Amazon Bedrock support
Elasticsearch open inference API added Amazon Bedrock support. Here's how to use Amazon Bedrock models via Elasticsearch's open inference API.