Blogs

Serverless semantic search with ELSER in Python: Exploring Summer Olympic games history
This blog shows how to fetch information from an Elasticsearch index, in a natural language expression, using semantic search. We will load previous olympic games data set and then use the ELSER model to perform semantic searches.
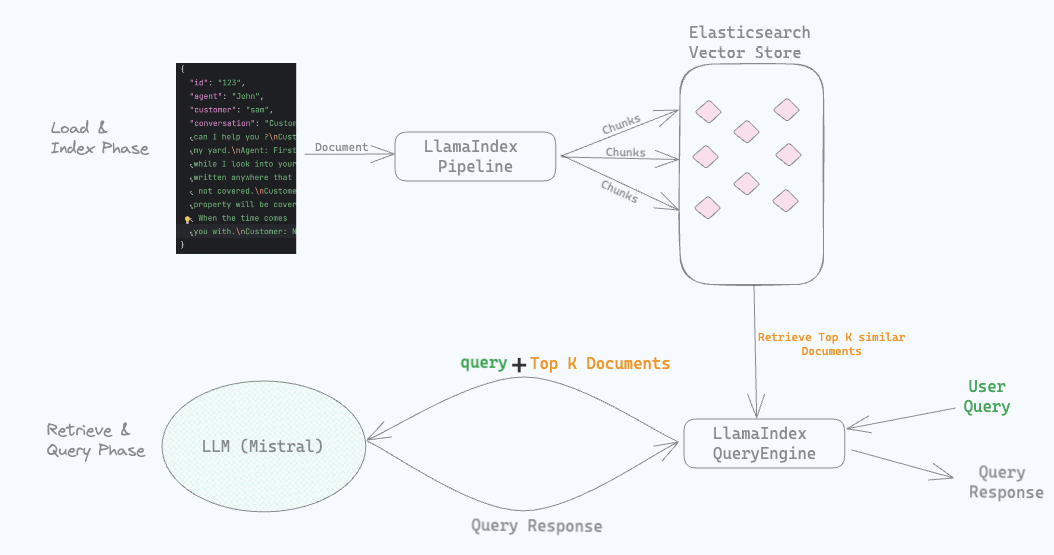
Protecting Sensitive and PII information in RAG with Elasticsearch and LlamaIndex
How to protect sensitive and PII data in a RAG application with Elasticsearch and LlamaIndex.

Building advanced visualizations with Kibana and Vega
Have you struggled to build the Kibana visualizations you need using Lens and TSDB? Learn how to create complex visualizations using Kibana and Vega.
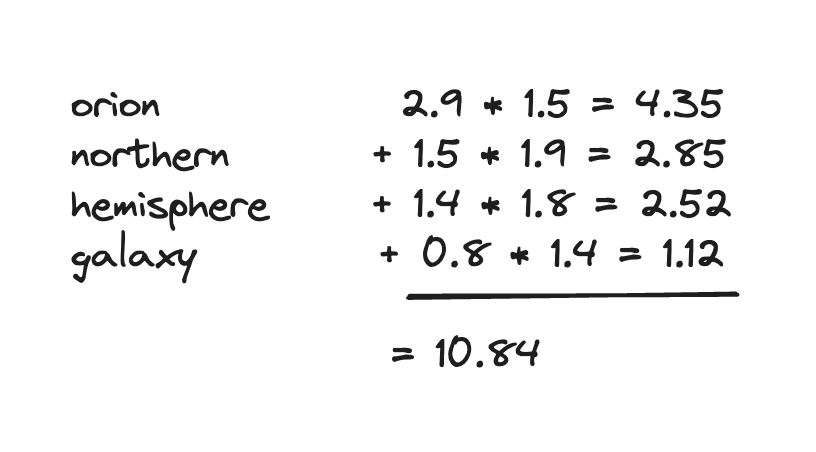
Introducing the sparse vector query: Searching sparse vectors with inference or precomputed query vectors
Introducing the sparse vector query, powering sparse vector search in the future

GenAI for Customer Support — Part 2: Building a Knowledge Library
This series gives you an inside look at how we're using generative AI in customer support. Join us as we share our journey in real-time!
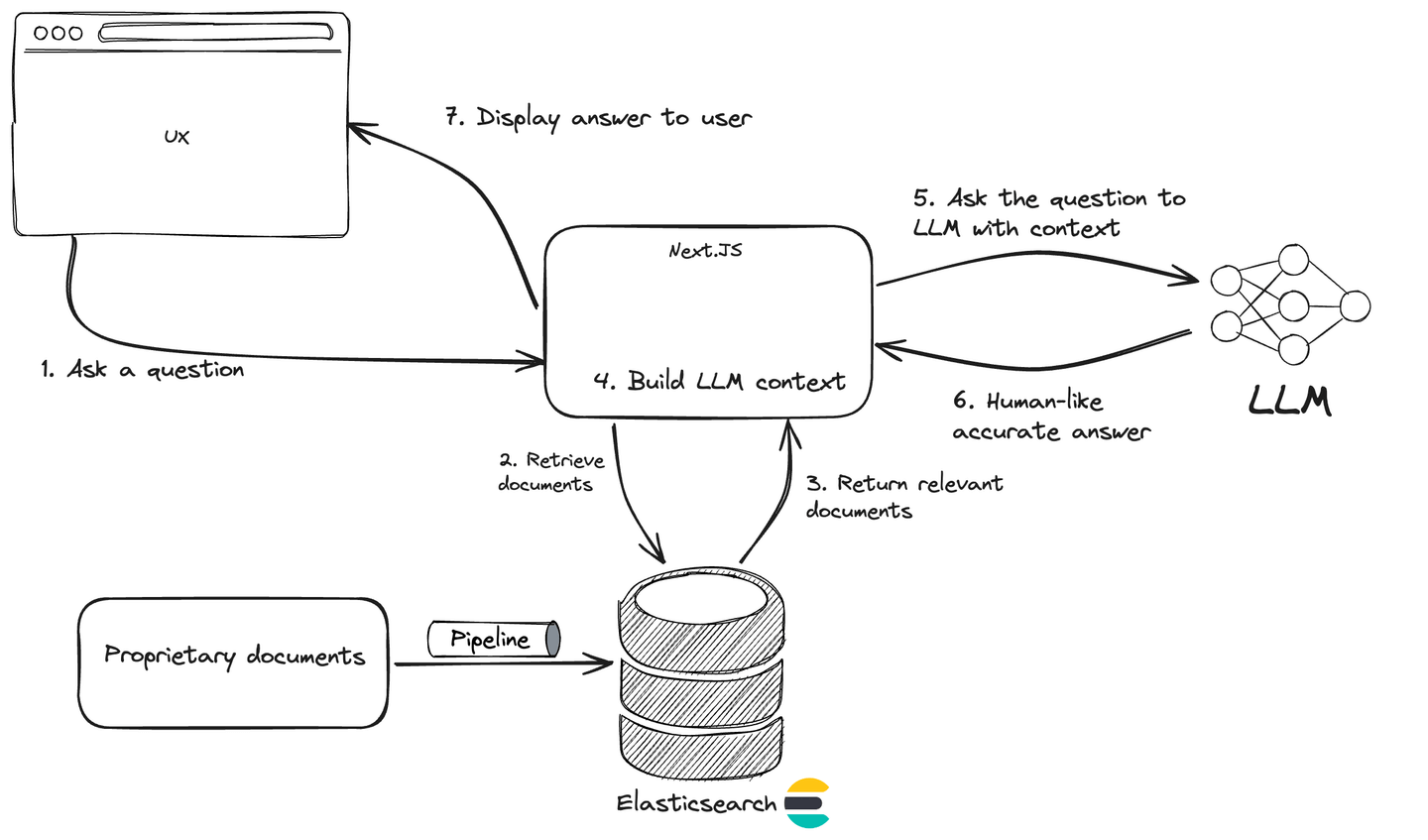
Build a Conversational Search for your Customer Success Application with Elasticsearch and OpenAI
Explore how to enhance your customer success application by implementing a conversational search feature using advanced technologies such as Large Language Models (LLMs) and Retrieval-Augmented Generation (RAG)
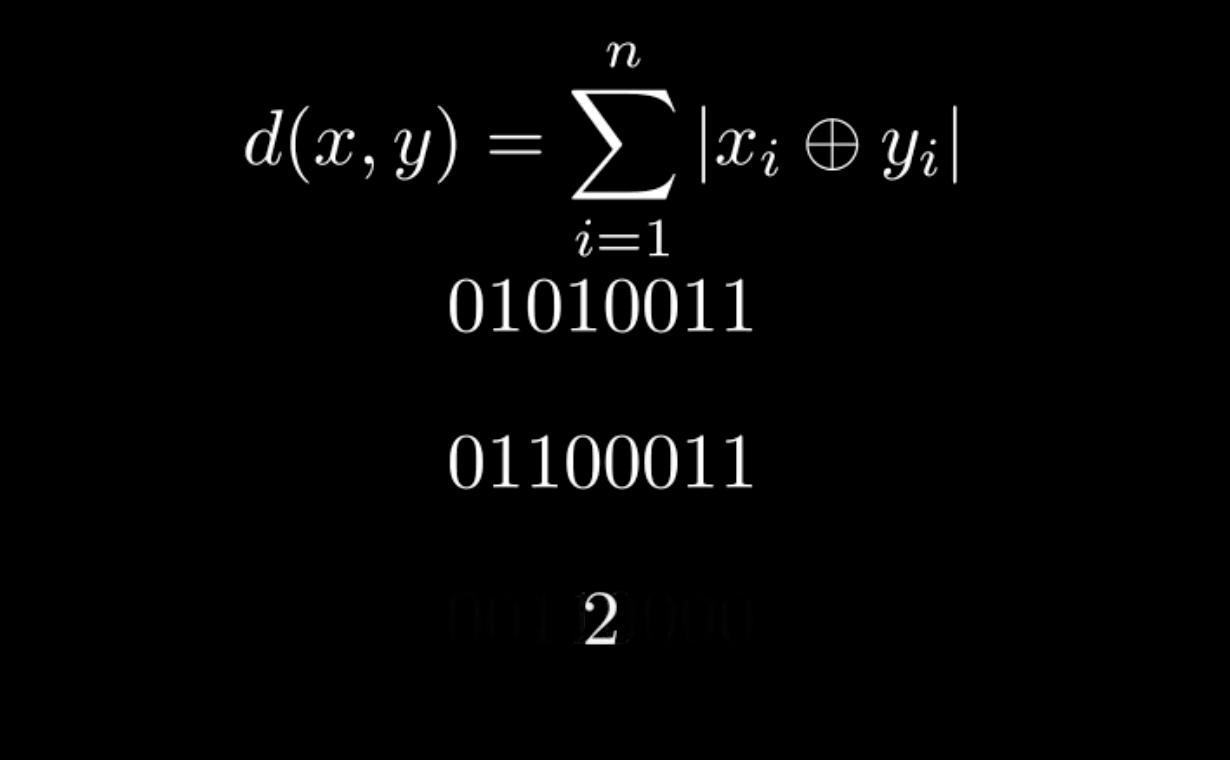
Bit vectors in Elasticsearch
What are bit vectors and how to use them in Elasticsearch

Evaluating search relevance - Part 1
How to evaluate your own search systems in the context of better understanding the BEIR benchmark, with specific tips and techniques to improve your search evaluation processes. Part 1 of the series.

Introducing Learning To Rank in Elasticsearch
Discover how to Learning To Rank can help you to improve your search ranking and how to implement it in Elasticsearch
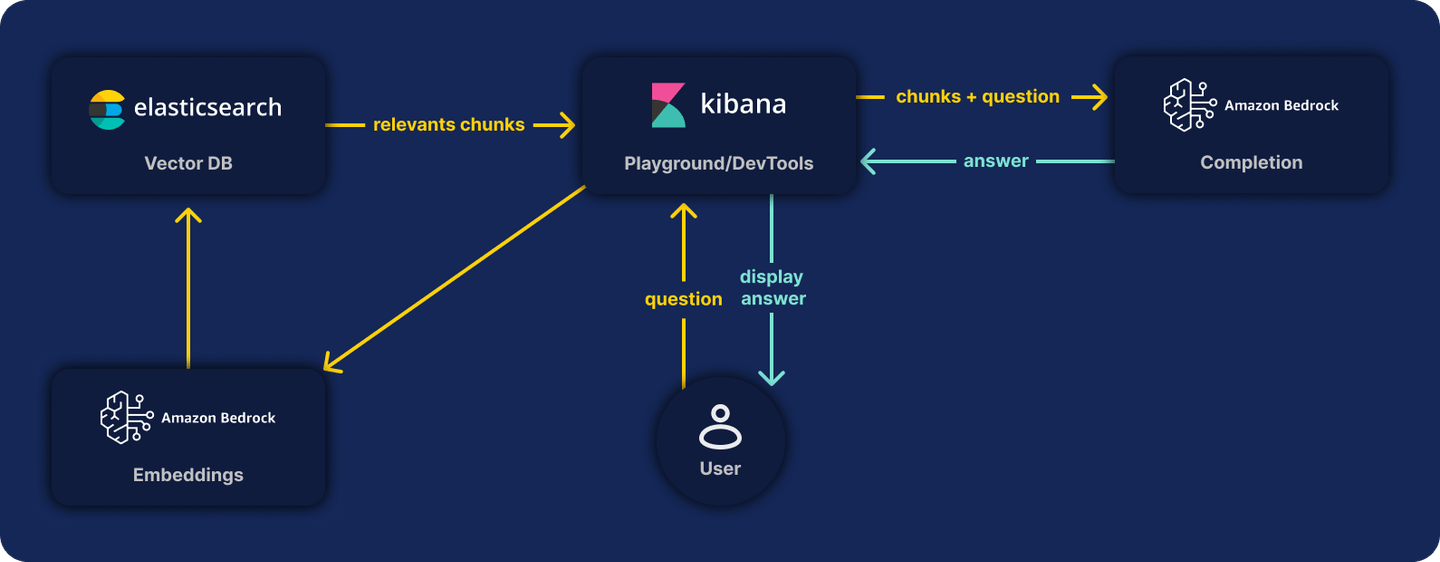
semantic_text with Amazon Bedrock
Using semantic_text new feature, and AWS Bedrock as inference endpoint service