ML Research

Exploring depth in a 'retrieve-and-rerank' pipeline
Select an optimal re-ranking depth for your model and dataset.

What is semantic reranking and how to use it?
Learn about the trade-offs using semantic reranking in search and RAG pipelines.

Better Binary Quantization 101
Understand what binary quantization is, how it works and its benefits. This guide also covers the math behind the quantization and examples.

Introducing Elastic Rerank: Elastic's new semantic re-ranker model
Learn about how Elastic's new re-ranker model was trained and how it performs

Evaluating search relevance part 2 - Phi-3 as relevance judge
Using the Phi-3 language model as a relevance judge, with tips & techniques to improve the agreement with human-generated annotation
Evaluating search relevance part 1 - The BEIR benchmark
Learn to evaluate your search system in the context of better understanding the BEIR benchmark, with tips & techniques to improve your search evaluation processes.

Evaluating scalar quantization in Elasticsearch
Learn how scalar quantization can be used to reduce the memory footprint of vector embeddings in Elasticsearch through an experiment.
Scalar quantization optimized for vector databases
Optimizing scalar quantization for the vector database use case allows us to achieve significantly better performance for the same retrieval quality at high compression ratios.

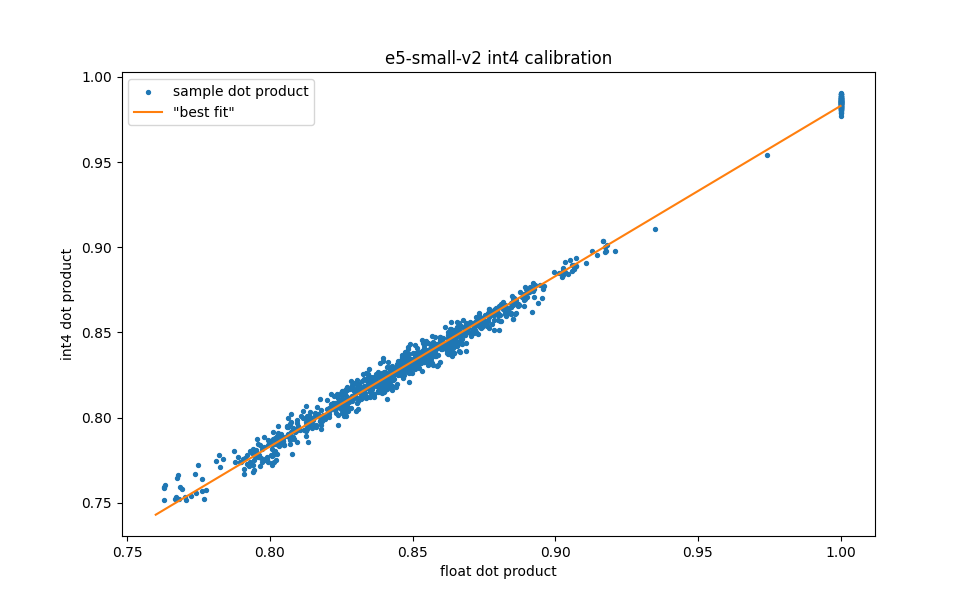
Understanding Int4 scalar quantization in Lucene
This blog explains how int4 quantization works in Lucene, how it lines up, and the benefits of using int4 quantization.

RAG evaluation metrics: A journey through metrics
Explore RAG evaluation metrics like BLEU score, ROUGE score, PPL, BARTScore, and more. Discover how Elastic is evaluating RAG with UniEval.