In this blog we will discuss how to implement Q&A experience using a RAG technique (Retrieval Augmented Generation) with Elasticsearch as a vector database. We will use LlamaIndex and a locally running Mistral LLM.
Before we get started we will look at some terminology.
Terminology
LlamaIndex is a leading data framework for building LLM (Large Language Model) applications. LlamaIndex provides abstractions for various stages of building a RAG (Retrieval Augmented Generation) application. Frameworks like LlamaIndex and LangChain provide abstractions so that applications don’t get tightly coupled to the APIs of any specific LLM.
Elasticsearch is offered by Elastic. Elastic is an industry leader behind Elasticsearch, a search and analytics engine that supports full text search for precision, vector search for semantic understanding, and hybrid search for the best of both worlds. Elasticsearch is a fully functional vector database. Elasticsearch capabilities we use in this blog are available in the Free and Open version of Elasticsearch.
Retrieval Augment Generation (RAG) is an AI technique/pattern where LLMs are provided with external knowledge to generate responses to user queries. This allows LLM responses to be tailored to specific context and responses are more specific.
Mistral provides both open-source and optimized, enterprise-grade LLM models. In this tutorial, we will use their open source model mistral-7b that runs on your laptop. If you don’t want to run the model on your laptop, alternatively you could use their cloud version in which case you will have to modify the code in this blog to use the right API keys and packages.
Ollama helps with running LLMs locally on your laptop. We will use Ollama to run the open source Mistral-7b model locally.
Embeddings are numerical representations of the meaning of text/media. They are lower-dimensional representations of high-dimensional information.
Building a RAG application with LlamaIndex, Elasticsearch & Mistral: Scenario overview
Scenario:
We have a sample dataset (as a JSON file) of call center conversations between agents and customers of a fictional Home insurance company. We will build a simple RAG application which can answer questions like
Give me summary of water related issues.
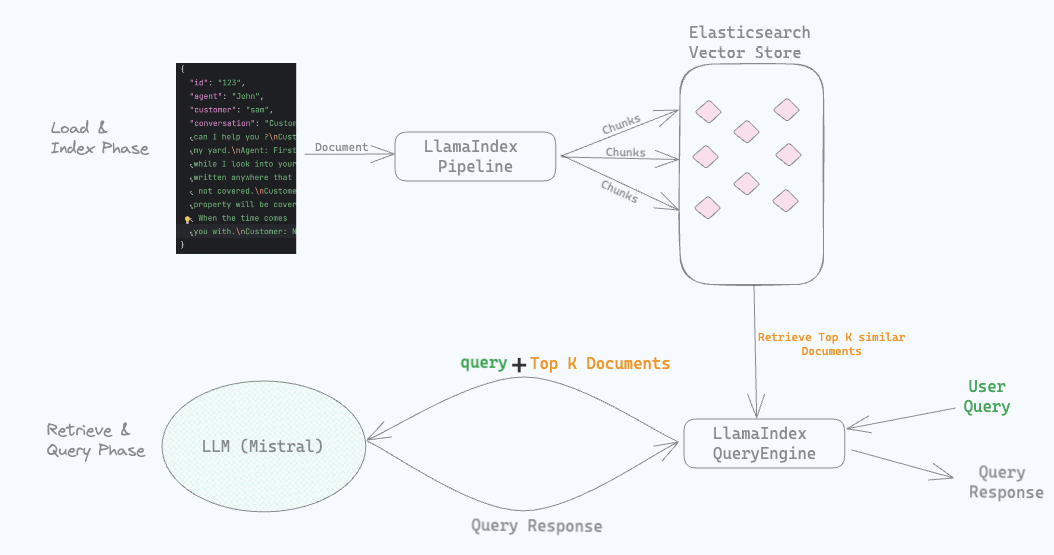
High level flow
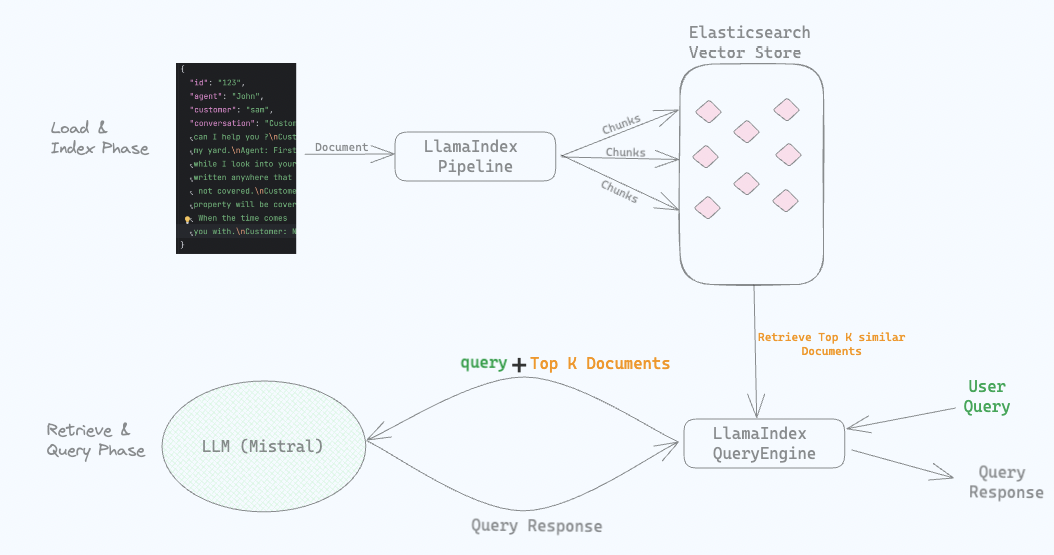
We have Mistral LLM running locally using Ollama.
Next, we load conversations from the JSON file as Documents into the ElasticsearchStore (which is a VectorStore backed by Elasticsearch). While loading the documents we create embeddings using the Mistral model running locally. We store these embeddings along with the conversations in LlamaIndex Elasticsearch vector Store (ElasticsearchStore).
We configure a LlamaIndex IngestionPipeline and supply it with the local LLM we use, in this case Mistral running via Ollama.
When we ask a question like “Give me summary of water related issues.”, Elasticsearch does a semantic search and returns conversations related to water issues. These conversations along with the original question are sent to the locally running LLM to generate an answer.
Steps in building the RAG application
Run Mistral locally
Download and install Ollama. After installing Ollama, run this command to download and run mistral
ollama run mistralIt might take a few minutes to download and run the model locally for the first time. Verify if mistral is running by asking a question like the below “Write a poem about clouds” and verify if the poem is of your liking. Keep ollama running as we will need to interact with the mistral model later through code.
Install Elasticsearch
Get Elasticsearch up and running either by creating a cloud deployment (instructions here) or by running in docker (instructions here). You can also create a production grade self-hosted deployment of Elasticsearch by starting here.
Assuming you are using the cloud deployment, grab the API Key and the Cloud ID for the deployment as mentioned in the instructions. We will use them later.
RAG application
For reference, entire code can be found in this Github Repository. Cloning the repo is optional as we will go through the code below.
In your favorite IDE, create a new Python application with the below 3 files.
-
index.pywhere code related to indexing data goes. -
query.pywhere code related to querying and LLM interaction goes. -
.envwhere configuration properties like API keys go.
We need to install a few packages. We begin by creating a new python virtual environment in the root folder of your application.
python3 -m venv .venvActivate the virtual environment and install the below required packages.
source .venv/bin/activate
pip install llama-index
pip install llama-index-embeddings-ollama
pip install llama-index-llms-ollama
pip install llama-index-vector-stores-elasticsearch
pip install sentence-transformers
pip install python-dotenvIndexing data
Download the conversations.json file which contains conversations between customers and call center agents of our fictionaly home insurance company. Place the file in the root directory of the application alongside the 2 python files and the .env file you created earlier. Below is an example of the contents of the file.
{
"conversation_id": 103,
"customer_name": "Sophia Jones",
"agent_name": "Emily Wilson",
"policy_number": "JKL0123",
"conversation": "Customer: Hi, I'm Sophia Jones. My Date of Birth is November 15th, 1985, Address is 303 Cedar St, Miami, FL 33101, and my Policy Number is JKL0123.\nAgent: Hello, Sophia. How may I assist you today?\nCustomer: Hello, Emily. I have a question about my policy.\nCustomer: There's been a break-in at my home, and some valuable items are missing. Are they covered?\nAgent: Let me check your policy for coverage related to theft.\nAgent: Yes, theft of personal belongings is covered under your policy.\nCustomer: That's a relief. I'll need to file a claim for the stolen items.\nAgent: We'll assist you with the claim process, Sophia. Is there anything else I can help you with?\nCustomer: No, that's all for now. Thank you for your assistance, Emily.\nAgent: You're welcome, Sophia. Please feel free to reach out if you have any further questions or concerns.\nCustomer: I will. Have a great day!\nAgent: You too, Sophia. Take care.",
"summary": "A customer inquires about coverage for stolen items after a break-in at home, and the agent confirms that theft of personal belongings is covered under the policy. The agent offers assistance with the claim process, resulting in the customer expressing relief and gratitude."
}We define a function called get_documents_from_file in index.py that reads the json file and creates a list of Documents. Document objects are the basic unit of information that LlamaIndex works with.
# index.py
import json, os
from llama_index.core import Document, Settings
from llama_index.core.node_parser import SentenceSplitter
from llama_index.core.ingestion import IngestionPipeline
from llama_index.embeddings.ollama import OllamaEmbedding
from llama_index.vector_stores.elasticsearch import ElasticsearchStore
from dotenv import load_dotenv
def get_documents_from_file(file):
"""Reads a json file and returns list of Documents"""
with open(file=file, mode='rt') as f:
conversations_dict = json.loads(f.read())
# Build Document objects using fields of interest.
documents = [Document(text=item['conversation'],
metadata={"conversation_id": item['conversation_id']})
for
item in conversations_dict]
return documentsCreate IngestionPipeline
Firstly, add the Elasticsearch CloudID and API keys that you obtained in the Install Elasticsearch section to the .env file. Your .env file should look like the below (with real values).
ELASTIC_CLOUD_ID=<REPLACE WITH YOUR CLOUD ID>
ELASTIC_API_KEY=<REPLACE WITH YOUR API_KEY>LlamaIndex IngestionPipeline lets you compose a pipeline using multiple components. Add the below code to the index.py file.
# index.py
# Load .env file contents into env
# ELASTIC_CLOUD_ID and ELASTIC_API_KEY are expected to be in the .env file.
load_dotenv('.env')
# ElasticsearchStore is a VectorStore that
# takes care of ES Index and Data management.
es_vector_store = ElasticsearchStore(index_name="calls",
vector_field='conversation_vector',
text_field='conversation',
es_cloud_id=os.getenv("ELASTIC_CLOUD_ID"),
es_api_key=os.getenv("ELASTIC_API_KEY"))
def main():
# Embedding Model to do local embedding using Ollama.
ollama_embedding = OllamaEmbedding("mistral")
# LlamaIndex Pipeline configured to take care of chunking, embedding
# and storing the embeddings in the vector store.
pipeline = IngestionPipeline(
transformations=[
SentenceSplitter(chunk_size=350, chunk_overlap=50),
ollama_embedding,
],
vector_store=es_vector_store
)
# Load data from a json file into a list of LlamaIndex Documents
documents = get_documents_from_file(file="conversations.json")
pipeline.run(documents=documents)
print(".....Done running pipeline.....\n")
if __name__ == "__main__":
main()As mentioned previously, the LlamaIndex IngestPipeline can be composed of multiple components. We are adding 3 components to the pipeline in the line pipeline = IngestionPipeline(....
-
SentenceSplitter: As can be seen in the definition of
get_documents_from_file(), each Document has a text field which holds the conversation found in the json file. This text field is a long piece of text. In order for semantic search to work well, it needs to be broken down into chunks of smaller texts. The SentenceSplitter class does this for us. These chunks are called Nodes in LlamaIndex terminology. There is metadata in the nodes that points back to the Document they belong to. Alternatively, you could use Elasticsearch Ingestpipeline for chunking as well as shown in this blog. -
OllamaEmbedding: Embedding models convert a piece of text into numbers (also called vectors). Having numerical representation allows us to run semantic search where search results match the meaning of the word rather than just doing a text search. We supply the IngestionPipeline with
OllamaEmbedding("mistral"). The chunks that we split using SentenceSplitter are sent to the Mistral model that is running on your local machine via Ollama, mistral then creates embeddings for the chunks. -
ElasticsearchStore: The LlamaIndex ElasticsearchStore vector store backs up the embeddings being created into an Elasticsearch Index. ElasticsearchStore takes care of creating and populating the contents of the specified Elasticsearch Index. While creating the ElasticsearchStore (referenced by
es_vector_store) we supply the name of the Elasticsearch Index we want to create (callsin our case), the field in the index where we want the embeddings to be stored (conversation_vectorin our case) and the field where we want to store the text (conversationin our case). In summary, based on our configurationElasticsearchStorecreates a new Index in Elasticsearch withconversation_vectorandconversationas fields (among other auto-created fields).
Tying it all together, we run the pipeline by calling pipeline.run(documents=documents).
Run the index.py script to execute the ingest pipeline:
python index.pyOnce the pipeline run is completed, we should see a new Index in Elasticsearch called calls. Running a simple elasticsearch query using the Dev Console you should be able to see data loaded along with the embeddings.
GET calls/_search?size=1To summarize what we did so far, we created Documents from a JSON file, we split them in chunks, created embeddings for those chunks and stored the embeddings (and the text conversation) in a vector store (ElasticsearchStore).
Querying
The llamaIndex VectorStoreIndex lets you retrieve relevant documents and query data. By default VectorStoreIndex stores embeddings in-memory in a SimpleVectorStore. However external vector stores (like ElasticsearchStore) can be used instead to make the embeddings persistent.
Open the query.py and paste the below code
# query.py
from llama_index.core import VectorStoreIndex, QueryBundle, Response, Settings
from llama_index.embeddings.ollama import OllamaEmbedding
from llama_index.llms.ollama import Ollama
from index import es_vector_store
# Local LLM to send user query to
local_llm = Ollama(model="mistral")
Settings.embed_model= OllamaEmbedding("mistral")
index = VectorStoreIndex.from_vector_store(es_vector_store)
query_engine = index.as_query_engine(local_llm, similarity_top_k=10)
query="Give me summary of water related issues"
bundle = QueryBundle(query, embedding=Settings.embed_model.get_query_embedding(query))
result = query_engine.query(bundle)
print(result)We define a local LLM (local_llm) to point to the Mistral model running on Ollama. Next, we create a VectorStoreIndex (index) from the ElasticssearchStore vector store we created earlier and then we get a query engine from the index. While creating the query engine we reference the local LLM that should be used to respond, we also supply (similarity_top_k=10) to configure the number of documents that should be retrieved from the vector store and sent to the LLM to get a response.
Run the query.py script to execute the RAG flow:
python query.pyWe send the query Give me summary of water related issues (feel free to customize the query) and the response from the LLM which is supplied with related Documents should be something like the below.
In the provided context, we see several instances where customers have inquired about coverage for damage related to water. In two cases, flooding caused damage to basements and roof leaks were the issue in another case. The agents confirmed that both types of water damage are covered under their respective policies. Therefore, water-related issues encompassing flooding and roof leaks are typically covered under home insurance policies.
Some caveats:
This blog post is a beginners introduction to the RAG technique with Elasticsearch and hence omits configuration of features that will enable you to take this starting point to production. When building for production use cases you will want to consider more sophisticated aspects like being able to protect your data with Document Level Security, chunking your data as part of an Elasticsearch Ingest pipeline or even running other ML jobs on the same data being used for GenAI/Chat/Q&A use cases.
You might also want to consider sourcing data and creating embeddings from various external sources (e.g Azure Blob Storage, Dropbox, Gmail etc) using Elastic Connectors.
Elastic makes all the above and more possible, and provides a comprehensive enterprise grade solution for GenAI use cases and beyond.
What’s next?
- You might have noticed that we are sending 10 related conversations along with the user question to the LLM to formulate a response. These conversations may contain PII (Personal Identifiable Information) like name, DOB, address etc. In our case the LLM is local so data leak is not an issue. However, when you want to use an LLM running in the cloud (E.g OpenAI) it is not desirable to send texts containing PII information. In a followup blog we will see how to accomplish Masking PII information before sending to external LLMs in the RAG flow.
- In this post we used a local LLM, in the upcoming post on Masking PII data in RAG, we will look at how we can easily switch from local LLM to a public LLM.