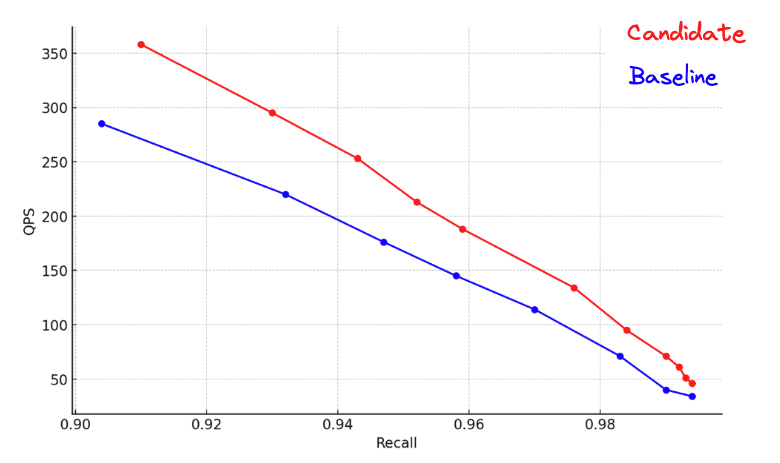
Automatic byte quantization in Lucene
While HNSW is a powerful and flexible way to store and search vectors, it does require a significant amount of memory to run quickly. For example, querying 1MM float32 vectors of 768 dimensions requires roughly of ram. Once you start searching a significant number of vectors, this gets expensive. One way to use around less memory is through byte quantization. Lucene and consequently Elasticsearch has supported indexing vectors for some time, but building these vectors has been the user's responsibility. This is about to change, as we have introduced scalar quantization in Lucene.
Scalar quantization 101
All quantization techniques are considered lossy transformations of the raw data. Meaning some information is lost for the sake of space. For an in depth explanation of scalar quantization, see: Scalar Quantization 101. At a high level, scalar quantization is a lossy compression technique. Some simple math gives significant space savings with very little impact on recall.
Exploring the architecture
Those used to working with Elasticsearch may be familiar with these concepts already, but here is a quick overview of the distribution of documents for search.
Each Elasticsearch index is composed of multiple shards. While each shard can only be assigned to a single node, multiple shards per index gives you compute parallelism across nodes.
Each shard is composed as a single Lucene Index. A Lucene index consists of multiple read-only segments. During indexing, documents are buffered and periodically flushed into a read-only segment. When certain conditions are met, these segments can be merged in the background into a larger segment. All of this is configurable and has its own set of complexities. But, when we talk about segments and merging, we are talking about read-only Lucene segments and the automatic periodic merging of these segments. Here is a deeper dive into segment merging and design decisions.
Quantization per segment in Lucene
Every segment in Lucene stores the following: the individual vectors, the HNSW graph indices, the quantized vectors, and the calculated quantiles. For brevity's sake, we will focus on how Lucene stores quantized and raw vectors. For every segment, we keep track of the raw vectors in the file, quantized vectors and a single corrective multiplier float in , and the metadata around the quantization within the file.

Figure 1: Simplified layout of raw vector storage file. Takes up of disk space since values are 4 bytes. Because we are quantizing, these will not get loaded during HNSW search. They are only used if specifically requested (e.g. brute-force secondary via rescore), or for re-quantization during segment merge.

Figure 2: Simplified layout of the file. Takes up of space and will be loaded into memory during search. The bytes is to account for the corrective multiplier float, used to adjust scoring for better accuracy and recall.

Figure 3: The simplified layout of the metadata file. Here is where we keep track of quantization and vector configuration along with the calculated quantiles for this segment.
So, for each segment, we store not only the quantized vectors, but the quantiles used in making these quantized vectors and the original raw vectors. But, why do we keep the raw vectors around at all?
Quantization that grows with you
Since Lucene periodically flushes to read only segments, each segment only has a partial view of all your data. This means the quantiles calculated only directly apply for that sample set of your entire data. Now, this isn't a big deal if your sample adequately represents your entire corpus. But Lucene allows you to sort your index in various ways. So, you could be indexing data sorted in a way that adds bias for per-segment quantile calculations. Also, you can flush the data whenever you like! Your sample set could be tiny, even just one vector. Yet another wrench is that you have control over when merges occur. While Elasticsearch has configured defaults and periodic merging, you can ask for a merge whenever you like via _force_merge API. So how do we still allow all this flexibility, while providing good quantization that provides good recall?
Lucene's vector quantization will automatically adjust over time. Because Lucene is designed with a read-only segment architecture, we have guarantees that the data in each segment hasn't changed and clear demarcations in the code for when things can be updated. This means during segment merge we can adjust quantiles as necessary and possibly re-quantize vectors.
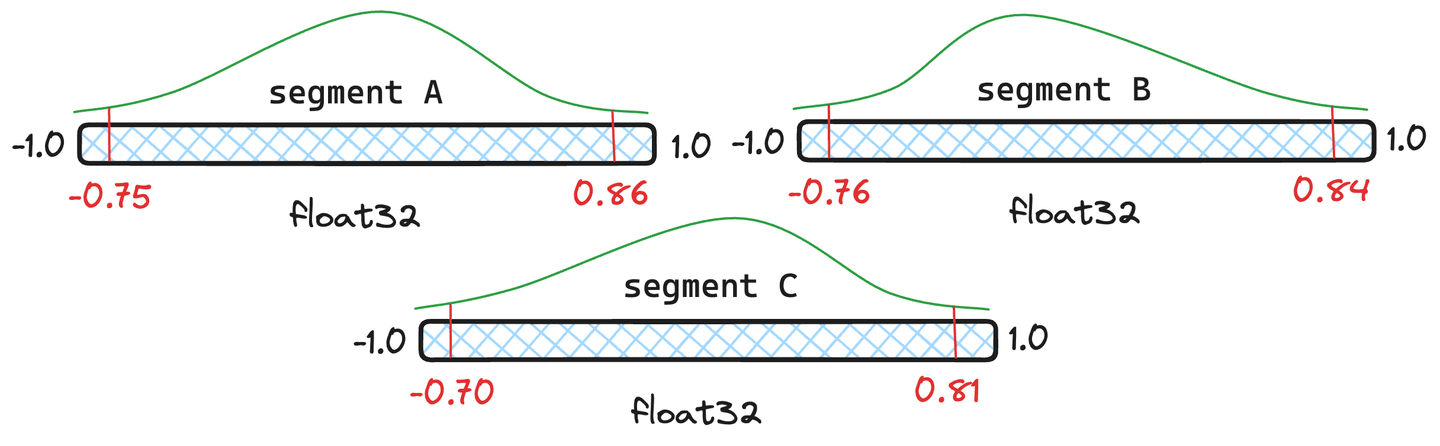
Figure 4: Three example segments with different quantiles.
But isn't re-quantization expensive? It does have some overhead, but Lucene handles quantiles intelligently, and only fully-requantizes when necessary. Let's use the segments in Figure 4 as an example. Let's give segments and documents each and segment only documents. Lucene will take a weighted average of the quantiles and if that resulting merged quantile is near enough to the segments original quantiles, we don't have to re-quantize that segment and will utilize the newly merged quantiles.
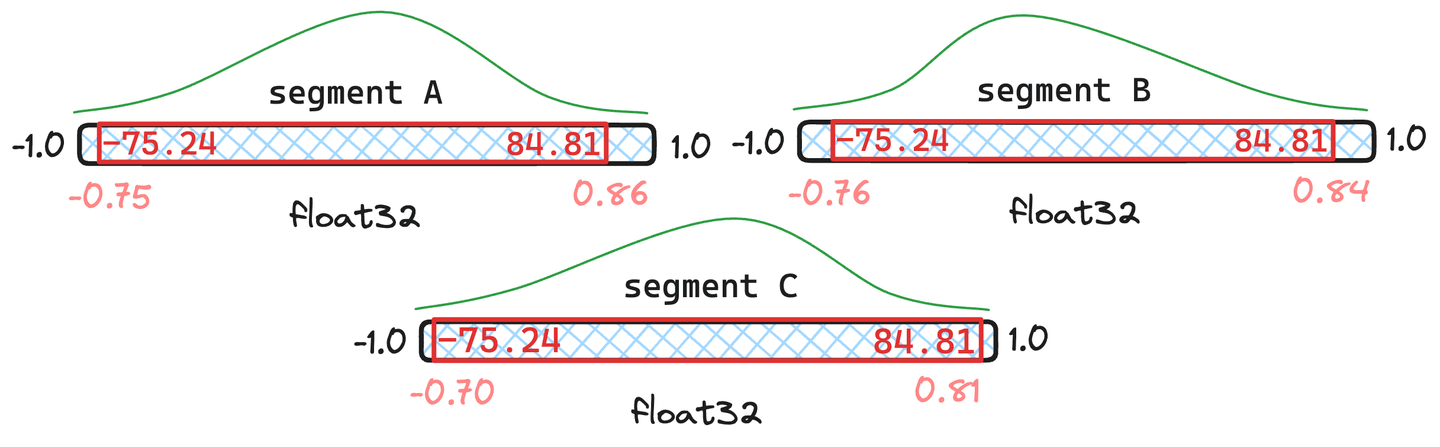
Figure 5: Example of merged quantiles where segments and have documents and only has .
In the situation visualized in figure 5, we can see that the resulting merged quantiles are very similar to the original quantiles in and . Thus, they do not justify quantizing the vectors. Segment , seems to deviate too much. Consequently, the vectors in would get re-quantized with the newly merged quantile values.
There are indeed extreme cases where the merged quantiles differ dramatically from any of the original quantiles. In this case, we will take a sample from each segment and fully re-calculate the quantiles.
Quantization performance & numbers
So, is it fast and does it still provide good recall? The following numbers were gathered running the experiment on a c3-standard-8 GCP instance. To ensure a fair comparison with we used an instance large enough to hold raw vectors in memory. We indexed Cohere Wiki vectors using maximum-inner-product.
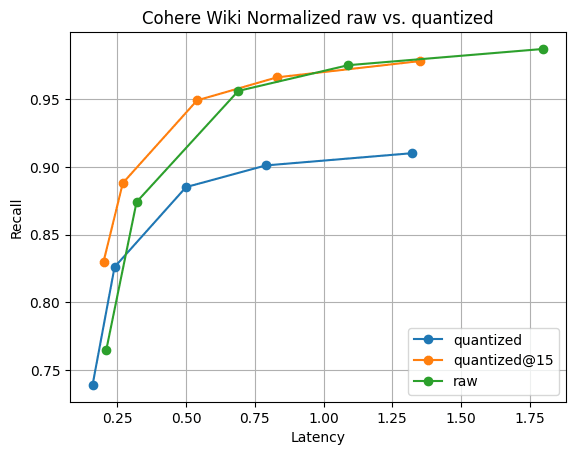
Figure 6: Recall@10 for quantized vectors vs raw vectors. The search performance of quantized vectors is significantly faster than raw, and recall is quickly recoverable by gathering just 5 more vectors; visible by .
Figure 6 shows the story. While there is a recall difference, as to be expected, it's not significant. And, the recall difference dissappears by gathering just 5 more vectors. All this with faster segment merges and 1/4 of the memory of vectors.
Conclusion
Lucene provides a unique solution to a difficult problem. There is no “training” or “optimization” step required for quantization. In Lucene, it will just work. There is no worry about having to “re-train” your vector index if your data shifts. Lucene will detect significant changes and take care of this automatically over the lifetime of your data. Look forward to when we bring this capability into Elasticsearch!