Chatbot Tutorial
In this tutorial you are going to build a large language model (LLM) chatbot that uses a pattern known as Retrieval-Augmented Generation (RAG).
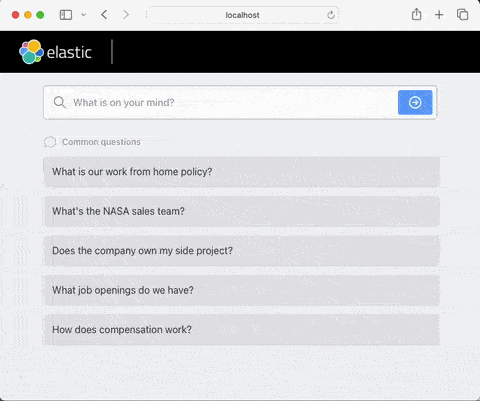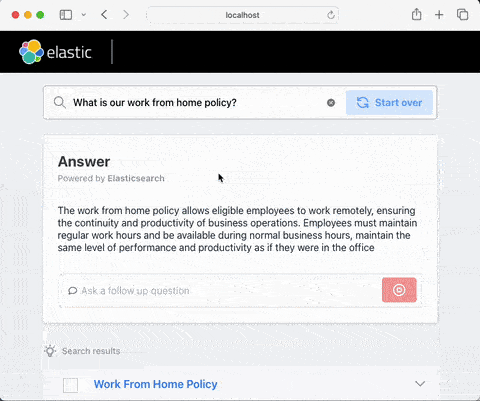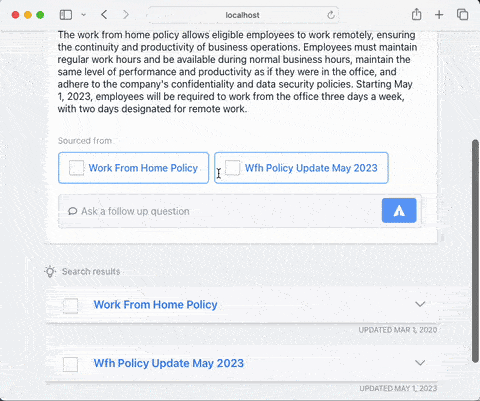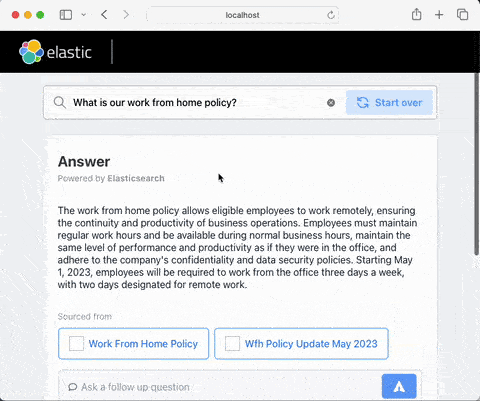
Chatbots built with RAG can overcome some of the limitations that general-purpose conversational models such as ChatGPT have. In particular, they are able to discuss and answer questions about:
- Information that is private to your organization.
- Events that were not part of the training dataset, or that took place after the LLM finished training.
As an additional benefit, RAG helps to "ground" LLMs with facts, making them less likely to make up a response or "hallucinate".
The secret to achieve this is to use a two-step process to obtain an answer from the LLM:
- First in the Retrieval Phase, one or more data sources are searched for the user's query,. The relevant documents that are found in this search are retrieved. Using an Elasticsearch index for this is a great option for this, enabling you to choose between keyword, dense and sparse vector search methods, or even a hybrid combination of them.
- Then in the Generation Phase, the user's prompt is expanded to include the documents retrieved in the first phase, with added instructions to the LLM to find the answer to the user's question in the retrieved information. The expanded prompt, including the added context for the question, is what is sent to the LLM in place of the original query.
Tutorial Structure
This tutorial is structured in two main parts.
In the first part, you will learn how to run the Chatbot RAG App example, a complete application featuring a Python back end and a React front end.
Once you have the example application up and running, the second part of this tutorial explains the different components of the RAG implementation, to allow you to adapt the example code to your own needs.